Hacking the Universe with Quantum Encraption
Ladies and Gentlemen of the Quantum Physics Community:
I want you to make a Pseudorandom Number Generator!
And why not! I’m just a crypto nerd working on computers, I only get a few discrete bits and a handful of mathematical operations. You have such an enormous bag of tricks to work with! You’ve got a continuous domain, trigonometry, complex numbers, eigenvectors…you could make a PRNG for the universe! Can you imagine it? Your code could be locally hidden in every electron, proton, fermion, boson in creation.
Don’t screw it up, though. I can’t possibly guess what chaos would (or would fail to) erupt, if multiple instances of a PRNG shared a particular seed, and emitted identical randomness in different places far, far away. Who knows what paradoxes might form, what trouble you might find yourself entangled with, what weak interactions might expose your weak non-linearity. Might be worth simulating all this, just to be sure.
After all, we wouldn’t want anyone saying, “Not even God can get crypto right”.
—–
Cryptographically Secure Pseudorandom Number Generators are interesting. Given a relatively small amount of data (just 128 bits is fine) they generate an effectively unlimited stream of bits completely indistinguishable from the ephemeral quantum noise of the Universe. The output is as deterministic as the digits of pi, but no degree of scientific analysis, no amount of sample data will ever allow a model to form for what bits will come next.
In a way, CSPRNGs represent the most practical demonstration of Godel’s First Incompleteness Theorem, which states that for a sufficiently complex system, there can be things that are true about it that can never be proven within the rules of that system. Science is literally the art of compressing vast amounts of experimentally derived output on the nature of things, to a beautiful series of rules that explains it. But as much as we can model things from their output with math, math can create things we can never model. There can be a thing that is true — there are hidden variables in every CSPRNG — but we would never know.
And so an interesting question emerges. If a CSPRNG is indistinguishable from the quantum noise of the Universe, how would we know if the quantum noise of the universe was not itself a CSPRNG? There’s an infinite number of ways to construct a Random Number Generator, what if Nature tried its luck and made one more? Would we know?
Would it be any good?
I have no idea. I’m just a crypto nerd. So I thought I’d look into what my “nerds from another herd”, Quantum Physicists, had discovered.
—–
Like most outsiders diving into this particular realm of science, I immediately proceeded to misunderstand what Quantum Physics had to say. I thought Bell’s Theorem ruled out anything with secret patterns:
“No physical theory of local hidden variables can ever reproduce all the predictions of quantum mechanics.”
I thought that was pretty strange. Cryptography is the industrial use of chaotic systems with hidden variables. I had read this to mean, if there were ever local hidden variables in the random data that quantum mechanics consumed, the predictions would be detectably different from experimental evidence.
Quantum Physics is cool, it’s not that cool. I have a giant set of toys for encrypting hidden variables in a completely opaque datastream, what, I just take my bits, put them into a Quantum Physics simulation, and see results that differ from experimental evidence? The non-existence of a detection algorithm distinguishing encrypted datastreams from pure quantum entropy, generic across all formulations and levels of complexity, might very well be the safest conjecture in the history of mathematics. If such a thing existed, it wouldn’t be one million rounds of AES we’d doubt, it’d be the universe.
Besides, there’s plenty of quantum mechanical simulations on the Internet, using JavaScript’s Math.Random. That’s not exactly a Geiger counter sitting next to a lump of Plutonium. This math needs uniform distributions, it does not at all require unpredictable ones.
But of course I completely misunderstood Bell. He based his theorem on what are now called Bell Inequalities. They describe systems that are in this very weird state known as entanglement, where two particles both have random states relative to the universe, but opposite states relative to eachother. It’s something of a bit repeat; an attacker who knows a certain “random” value is 1 knows that another “random” value is 0. But it’s not quite so simple. The classical interpretation of entanglement often demonstrated in relation to the loss of a shoe (something I’m familiar with, long story). You lose one shoe, the other one is generally identical.
But Bell inequalities, extravagantly demonstrated for decades, demonstrate that’s just not how things work down there because the Universe likes to be weird. Systems at that scale don’t have a ground truth, as much as a range of possible truths. Those two particles that have been entangled, it’s not their truth that is opposite, it’s their ranges. Normal cryptanalysis isn’t really set up to understand that — we work in binaries, 1’s and 0’s. We certainly don’t have detectors that can be smoothly rotated from “detects 1’s” to “detects 0’s”, and if we did we would assume as they rotated there would be a linear drop in 1’s detected matching a linear increase in 0’s.
When we actually do the work, though, we never see linear relationships. We always see curves, cos^2 in nature, demonstrating that the classical interpretation is wrong. There are always two probability distributions intersecting.
—–
Here’s the thing, and I could be wrong, but maybe I’ll inspire something right. Bell Inequalities prove a central thesis of quantum mechanics — that reality is probabilistic — but Bell’s Theorem speaks about all of quantum mechanics. There’s a lot of weird stuff in there! Intersecting probability distributions is required, the explanations that have been made for them are not necessarily necessary.
More to the point, I sort of wonder if people think it’s “local hidden variables” XOR “quantum mechanics” — if you have one, you can’t have the other. Is that true, though? You can certainly explain at least Bell Inequalities trivially, if the crystal that is emitting entangled particles emits equal and opposite polarizations, on average. In other words, there’s a probability distribution for each photon’s polarization, and it’s locally probed at the location of the crystal, twice.
I know, it would seem to violate conservation of angular momentum. But, c’mon. There’s lots of spare energy around. It’s a crystal, they’re weird, they can get a tiny bit colder. And “Nuh-uh-uh, Isaac Newton! For every action, there is an equal and opposite probability distribution of a reaction!” is really high up on the index of Shit Quantum Physicists Say.
Perhaps more likely, of course, is that there’s enough hidden state to bias the probability distribution of a reaction, or is able to fully describe the set of allowable output behaviors for any remote unknown input. Quantum Physics biases random variables. It can bias them more. What happens to any system with a dependency on random variables that suddenly aren’t? Possibly the same thing that happens to everything else.
Look. No question quantum mechanics is accurate, it’s predictive of large chunks of the underlying technology the Information Age is built on. The experiment is always right, you’re just not always sure what it’s right about. But to explain the demonstrable truths of probability distribution intersection, Quantum Physicists have had to go to some pretty astonishing lengths. They’ve had to bend on the absolute speed limit of the universe, because related reactions were clearly happening in multiple places in a manner that would require superluminal (non-)communication.
I guess I just want to ask, what would happen if there’s just a terrible RNG down there — non-linear to all normal analysis, but repeat its seed in multiple particles and all hell breaks loose? No really, what would happen?
Because that is the common bug in all PRNGs, cryptographically secure and otherwise. Quantum mechanics describes how the fundamental unstructured randomness of the universe is shaped and structured into probability distributions. PRNGs do the opposite — they take structure, any structure, even fully random bits limited only by their finite number — and make them an effectively unbound stream indistinguishable from what the Universe has to offer.
The common PRNG bug is that if the internal state is repeated, if the exact bits show up in the same places and the emission counter (like the digit of pi requested) is identical, you get repeated output.
I’m not saying quantum entanglement demonstrates bad crypto. I wouldn’t know. Would you?
Because here’s the thing. I like quantum physics. I also like relativity. The two fields are both strongly supported by the evidence, but they don’t exactly agree with one another. Relativity requires nothing to happen faster than the speed of light; Quantum Physics kind of needs its math to work instantaneously throughout the universe. A sort of detente has been established between the two successful domains, called the No Communication theorem. As long as only the underlying infrastructure of quantum mechanics needs to go faster than light, and no information from higher layers can be transmitted, it’s OK.
It’s a decent hack, not dissimilar to how security policies never seem to apply to security systems. But how could that even work? Do particles (or waves, or whatever) have IP addresses? Do they broadcast messages throughout the universe, and check all received messages for their identifier? Are there routers to reduce noise? Do they maintain some sort of line of sight at least? At minimum, there’s some local hidden variable even in any non-local theory, because the system has to decide who to non-locally communicate with. Why not encode a LUT (Look Up Table) or a function that generates the required probability distributions for all possible future interactions, thus saving the horrifying complexity of all particles with network connections to all other particles?
Look, one can simulate weak random number generators in each quantum element, and please do, but I think non-locality must depend on some entirely alien substrate, simulating our universe with a speed of light but choosing only to use that capacity for its own uses. The speed of light itself is a giant amount of complexity if instantaneous communication is available too.
Spooky action at a distance, time travel, many worlds theories, simulators from an alien dimension…these all make for rousing episodes of Star Trek, but cryptography is a thing we actually see in the world on a regular basis. Bad cryptography, even more so.
—-
I mentioned earlier, at the limit, math may model the universe, but our ability to extract that math ultimately depends on our ability to comprehend the patterns in the universe’s output. Math is under no constraint to grant us analyzable output.
Is the universe under any constraint to give us the amount of computation necessary to construct cryptographic functions? That, I think, is a great question.
At the extreme, the RSA asymmetric cipher can be interpreted symmetrically as F(p,q)==n, with p and q being large prime numbers and F being nothing more than multiply. But that would require the universe to support math on numbers hundreds of digits long. There’s a lot of room at the bottom but even I’m not sure there’s that much. There’s obviously some mathematical capacity, though, or else there’d be nothing (and no one) to model.
It actually doesn’t take that much to create a bounded function that resists (if not perfectly) even the most highly informed degree of relinearizing statistical work, cryptanalysis. This is XTEA:
/* take 64 bits of data in v[0] and v[1] and 128 bits of key[0] - key[3] */ void encipher(unsigned int num_rounds, uint32_t v[2], uint32_t const key[4]) { unsigned int i; uint32_t v0=v[0], v1=v[1], sum=0, delta=0x9E3779B9; for (i=0; i < num_rounds; i++) { v0 += (((v1 << 4) ^ (v1 >> 5)) + v1) ^ (sum + key[sum & 3]); sum += delta; v1 += (((v0 << 4) ^ (v0 >> 5)) + v0) ^ (sum + key[(sum>>11) & 3]); } v[0]=v0; v[1]=v1; }
(One construction for PRNGs, not the best, is to simply encrypt 1,2,3… with a secret key. The output bits are your digits, and like all PRNGs, if the counter and key repeat, so does the output.)
The operations we see here are:
- The use of a constant. There are certainly constants of the universe available at 32 bits of detail.
- Addition. No problem.
- Bit shifts. So that’s two things — multiplication or division by a power of two, and quantization loss of some amount of data. I think you’ve got that, it is called quantum mechanics after all.
- XOR and AND. This is tricky. Not because you don’t have exclusion available — it’s not called Pauli’s Let’s Have A Party principle — but because these operations depend on a sequence of comparisons across power of two measurement agents, and then combining the result. Really easy on a chip, do you have that kind of magic in your bag of tricks? I don’t know, but I don’t think so.
There is a fifth operation that is implicit, because this is happening in code. All of this is happening within a bitvector 32 bits wide, or GF(2^32), or % 2**32, depending on which community you call home. Basically, all summation will loop around. It’s OK, given the proper key material there’s absolutely an inverse function that will loop backwards over all these transformations and restore the original state (hint, hint).
Modular arithmetic is the math of clocks, so of course you’d expect it to exist somewhere in a world filled with things that orbit and spin. But, in practical terms, it does have a giant discontinuity as we approach 1 and reset to 0. I’m sure that does happen — you either do have escape velocity and fly off into the sunset, or you don’t, crash back to earth, and *ahem* substantially increase your entropy — but modular arithmetic seems to mostly express at the quantum scale trigonometrically. Sine waves can possibly be thought of as a “smoothed” mod, that exchanges sharp edges for nice, easy curves.
Would trig be an improvement to cryptography? Probably not! It would probably become way easier to break! While the universe is under no constraint to give you analyzable results, it’s also under no constraint not to. Crypto is hard even if you’re trying to get it right; randomly throwing junk together will (for once) not actually give you random results.
And not having XOR or AND is something notable (a problem if you’re trying to hide the grand secrets of the universe, a wonderful thing if you’re trying to expose them). We have lots of functions made out of multiply, add, and mod. They are beloved by developers for the speed at which they execute. Hackers like ‘em too, they can be predicted and exploited for remote denial of service attacks. A really simple function comes from the legendary Dan Bernstein:
unsigned djb_hash(void *key, int len) { unsigned char *p = key; unsigned h = 0; int i; for (i = 0; i < len; i++) { h = 33 * h + p[i]; } return h; }
You can see the evolution of these functions at http://www.eternallyconfuzzled.com/tuts//jsw_tut_hashing.aspx , what should be clear is that there are many ways to compress a wide distribution into a small one, with various degrees of uniformity and predictability.
Of course, Quantum Physicists actually know what tools they have to model the Universe at this scale, and their toolkit is vast and weird. A very simple compression function though might be called Roulette — take the sine of a value with a large normal or Poisson distribution, and emit the result. The output will be mostly (but not quite actually) uniform.
Now, such a terrible RNG would be vulnerable to all sorts of “chosen plaintext” or “related key” attacks. And while humans have learned to keep the function static and only have dynamic keys if we want consistent behavior, wouldn’t it be tragic if two RNGs shipped with identical inputs, one with a RNG configured for sine waves, the other configured for cosine? And then the results were measured against one another? Can you imagine the unintuitive inequalities that might form?
Truly, it would be the original sin.
—–
I admit it. I’m having fun with this (clearly). Hopefully I’m not being too annoying. Really, finally diving into the crazy quantum realm has been incredibly entertaining. Have you ever heard of Young’s experiment? It was something like 1801, and he took a pinhole of sunlight coming through a wall and split the light coming out of it with a note card. Boom! Interference pattern! Proved the existence of some sort of wave nature for light, with paper, a hole, and the helpful cooperation of a nearby stellar object. You don’t always need a particle accelerator to learn something about the Universe..
You might wonder why I thought it’d be interesting to look at all this stuff. I blame Nadia Heninger. She and her friends discovered that about (actually, at least) one in two hundred private cryptographic keys were actually shared between systems on the Internet, and were thus easily computed. Random number generation had been shown to have not much more than two nines of reliability in a critical situation. A lot of architectures for better RNG had been rejected, because people were holding out for hardware. Now, of course, we actually do have decent fast RNG in hardware, based on actual quantum noise. Sometimes people are even willing to trust it.
Remember, you can’t differentiate the universe from hidden variable math, just on output alone.
So I was curious what the de minimus quantum RNG might look like. Originally I wanted to exploit the fact that LEDs don’t just emit light, they generate electricity when illuminated. That shouldn’t be too surprising, they’re literally photodiodes. Not very good ones, but that’s kind of the charm here. I haven’t gotten that working yet, but what has worked is:
- An arduino
- A capacitor
- There is no 3
It’s a 1 Farad, 5V capacitor. It takes entire seconds to charge up. I basically give it power until 1.1V, and let it drain to 1.0V. Then I measure, with my nifty 10 bit ADC, just how much voltage there is per small number of microseconds.
Most, maybe all TRNGs, come down to measuring a slow clock with a fast clock. Humans are pretty good at keeping rhythm at the scale of tens of milliseconds. Measure us to the nanosecond, and that’s just not what our meat circuits can do consistently.
How much measurement is enough? 10 bits of resolution to model the behavior of trillions of electrons doesn’t seem like much. There’s structure in the data of course, but I only need to think I have about 128 bits before I can do what you do, and seed a CSPRNG with the quantum bits. It’ll prevent any analysis of the output that might be, you know, correlated with temperature or power line conditions or whatnot.
And that’s the thing with so-called True RNGs, or TRNGs. Quantum Physics shapes the fundamental entropy of the universe, whether you like it or not, and acts as sort of a gateway filter to the data you are most confident lacks any predictable structure, and adds predictable structure. So whenever we build a TRNG, we always overcollect, and very rarely directly expose. The great thing about TRNGs is — who knows what junk is in there? The terrifying thing about TRNGs is, not you either.
In researching this post, I found the most entertaining paper: Precise Monte Carlo Simulation of Single Photon Detectors (https://arxiv.org/pdf/1411.3663.pdf). It had this quote:
Using a simple but very demanding example of random number generation via detection of Poissonian photons exiting a beam splitter, we present a Monte Carlo simulation that faithfully reproduces the serial autocorrelation of random bits as a function of detection frequency over four orders of magnitude of the incident photon flux.
See, here is where quantum nerds and crypto nerds diverge.
Quantum nerds: “Yeah, detectors suck sometimes, universe is fuzzy whatcha gonna do”
Crypto nerds: “SERIAL AUTOCORRELATION?! THAT MEANS YOUR RANDOM BITS ARE NOT RANDOM”
Both are wrong, both are right, damn superposition. It might be interesting to investigate further.
—–
You may have noticed throughout this post that I use the phrase randomness, instead of entropy. That is because entropy is a term that cryptographers borrowed from physicists. For us, entropy is just an abstract measure of how much we’d have to work if we threw up our hands on the whole cryptanalysis enterprise and just tried every possibility. For experimental physicists, entropy is something of a thing, a condition, that you can remove from a system like coal on a cart powered by a laser beam.
Maybe we should do that. Let me explain. There is a pattern, when we’re attacking things, that the closer you get to the metal the more degrees of freedom you have to mess with its normal operations. One really brutal trick involves bypassing a cryptographic check, by letting it proceed as expected in hardware, and then just not providing enough electrons to the processor at the very moment it needs to report the failure. You control the power, you control the universe.
Experimental physicists control a lot of this particular universe. You know what sort of cryptographic attack we very rarely get to do? A chosen key attack.
Maybe we should strip as much entropy from a quantum system as physically possible, and see just how random things are inside the probability distributions that erupt upon stimulation. I don’t think we’ll see any distributional deviations from quantum mechanics, but we might see motifs (to borrow a phrase from bioinformatics) — sequences of precise results that we’ve seen before. Course grain identity, fine grain repeats.
Worth taking a look. Obviously, I don’t need to tell physicists how to remove entropy from their system. But it might be worth mentioning, if you make things whose size isn’t specified to matter, a multiple of prime integer relationships to a size that is known to be available to the system, you might see unexpected peaks as integer relationships in unknown equations expose as sharing factors with your experimental setup. I’m not quite sure you’ll find anything, and you’ll have to introduce some slop (and compensate for things like signals propagating at different speeds as photons in free space or electronic vibrations within objects) maybe, if this isn’t already common exploratory experimental process, you’ll find something cool.
—
I know, I’m using the standard hacker attack patterns where they kind of don’t belong. Quantum Physics has been making some inroads into crypto though, and the results have been interesting. If you think input validation is hard now, imagine if packet inspection was made illegal by the laws of the Universe. There was actually this great presentation at CCC a few years ago that achieved 100% key recovery on common quantum cryptographic systems — check it out.
So maybe there’s some links between our two worlds, and you’ll grant me some leeway to speculate wildly (if you’ve read this far, I’m hoping you already have). Let’s imagine for a moment, that in the organization I’ll someday run with a small army dedicated to fixing the Internet, I’ve got a couple of punk experimentalist grad students who know their way around an optics table and still have two eyes. What would I suggest they do?
I see lots of experiments providing positive confirmation of quantum mechanics, which is to be expected because the math works. But you know, I’d try something else. A lot of the cooler results from Quantum Physics show up in the two slit experiment, where coherent light is shined through two slits and interferes as waves on its way to a detector. It’s amazing, particularly since it shows up even when there’s only one photon, or one electron, going through the slits. There’s nothing else to interfere with! Very cool.
There’s a lot of work going on in showing interference patterns in larger and larger things. We don’t quite know why the behaviors correctly predicted by Quantum Physics don’t show up in, like, baseballs. The line has to be somewhere, we don’t know why or where. That’s interesting work! I might do something else, though.
There exists an implemented behavior: An interference pattern. It is fragile, it only shows up in particular conditions. I would see what breaks that fragile behavior, that shouldn’t. The truth about hacking is that as creative as it is, it is the easy part. There is no human being on the planet that can assemble a can of Coca-Cola, top to bottom. Almost any person can destroy a can though, along with most of the animal kingdom and several natural processes.
So yes. I’m suggesting fuzzing quantum physics. For those who don’t know, a lot of systems will break if you just throw enough crap at the wall. Eventually you’ll hit some gap between the model a developer had in his mind for what his software did, and what behaviors he actually shipped.
Fuzzing can be completely random, and find lots of problems. But one of the things we’ve discovered over the years is that understanding what signals a system is used to processing, and composing them in ways a system is not used to processing, exposes all sorts of failure conditions. For example, I once fuzzed a particular web browser. Those things are huge! All sorts of weird parsers, that can be connected in almost but not quite arbitrary ways. I would create these complex trees of random objects, would move elements from one branch to another, would delete a parent while working on a child, and all the while, I’d stress the memory manager to make sure the moment something was apparently unneeded, it would be destroyed.
I tell you, I’d come to work the next day and it’d be like Christmas. I wonder what broke today! Just because it can compose harmlessly, does not at all mean it will. Shared substrates like the universe of gunk lashing a web browser together never entirely implement their specifications perfectly. The map is not the territory, and models are always incomplete.
Here’s the thing. We had full debuggers set up for our fuzzers. We would always know exactly what caused a particular crash. We don’t have debuggers for reality at the quantum scale, though wow, I wish we did. Time travel debugging would be awesome.
I want to be cautious here, but I think this is important to say. Without a debugger, many crashes look identical. You would not believe the number of completely different things that can cause a web browser to give up the ghost. Same crash experience every time, though. Waves, even interference waves, are actually a really generic failure mode. The same slits that will pass photons, will also pass air molecules, will also pass water molecules. Stick enough people in a stadium and give them enough beer and you can even make waves out of people.
They’re not the same waves, they don’t have the same properties, that’s part of the charm of Quantum Physics. Systems at different scales do behave differently. The macro can be identical, the micro can be way, way different.
Interference is fairly intuitive for multi-particle systems. Alright, photons spin through space, have constructive and destructive modes when interacting in bulk, sure. It happens in single photon and electron systems too, though. And as much as I dislike non-locality, the experiment is always right. These systems behave as if they know all the paths they could take, and choose one.
This does not necessarily need to be happening for the same reasons in single photon systems, as it is in long streams of related particles. It might be! But, it’s important to realize, there won’t just be waves from light, air, and water. Those waves will have similarities, because while the mechanisms are completely different, the ratios that drive them remain identical (to the accuracy of each regime).
Bug collisions are extremely annoying.
I know I’m speaking a bit out of turn. It’s OK. I’m OK with being wrong, I just generally try to not be, you know. Not even wrong. What’s so impressive about superposition is that the particle behaves in a manner that belies knowledge it should not have. No cryptographic interpretation of the results of Quantum Physics can explain that; you cannot operate on data you do not have. Pilot wave theory is a deterministic conception of quantum physics, not incompatible at all with this cryptographic conjecture, but it too has given up on locality. You need to have an input, to account for it in your output.
But the knowledge of the second slit is not necessarily absent from the universe as perceived by the single photon. Single photon systems aren’t. It’s not like they’re flying through an infinitely dark vacuum. There’s black body radiation everywhere, bouncing off the assembly, interfering through the slits, making a mess of things. I know photons aren’t supposed to feel the force of others at different wavelengths, but we’re talking about the impact on just one. Last I heard, there’s a tensor field of forces everything has to go through, maybe it’s got a shadow. And the information required is some factor of the ratio between slits, nothing else. It’s not nothing but it’s a single value.
The single particle also needs to pass through the slits. You know, there are vibratory modes. Every laser assembly I see isolates the laser from the world. But you can’t stop the two slits from buzzing, especially when they’re being hit by all those photons that don’t miss the assembly. Matter is held together by electromagnetic attraction; a single photon versus a giant hunk of mass has more of an energy differential than myself and Earth. There doesn’t need to be much signal transfer there, to create waves. There just needs to be transfer of the slit distance.
Might be interesting to smoothly scale your photon count from single photon in the entire assembly (not just reaching the photodetector), through blindingly bright, and look for discontinuities. Especially if you’re using weak interactions to be trajectory aware.
In general, change things that shouldn’t matter. There are many other things that have knowledge of the second photon path. Reduce the signal so that there’s nothing to work on, or introduce large amounts of noise so it doesn’t matter that the data is there. Make things hot, or cold. Introduce asymmetric geometries, make a photon entering the left slit see a different (irrelevant) reality than the photon entering the right. As in, there are three slits, nothing will even reach the middle slit because it’s going to be blocked by a mirror routing it to the right slit, but the vibratory mode between left and middle is different than that for middle and right. Or at least use different shapes between the slits, so that the vibratory paths are longer than crow flies distance. Add notch filters and optical diodes where they shouldn’t do anything. Mirrors and retroreflectors too. Use weird materials — ferromagnetic, maybe, or anti-ferromagnetic. Bismuth needs its day in the sun. Alter density, I’m sure somebody’s got some depleted uranium around, gravity’s curvature of space might not be so irrelevant. Slits are great, they’re actually not made out of anything! You know what might be a great thing to make two slits out of? Three photodetectors! Actually, cell phones have gotten chip sensors to be more sensitive than the human eye, which in the right conditions is itself a single photon detector. I wonder just what a Sony ISX-017 (“Starvis”) can do.
You know what’s not necessarily taking nanoseconds to happen? Magnetization! It can occur in femtoseconds and block an electron from the right slit while the left slit is truly none the wiser. Remember, you need to try each mechanism separately, because the failure mode of anything is an interference pattern.
Just mess with it! Professors, tell your undergrads, screw things up. Don’t set anything on fire. You might not even have to tell them that.
And then you go set something on fire, and route your lasers through it. Bonus points if they’re flaming hoops. You’ve earned it.
I’ll be perfectly honest. If any of this works, nobody would be more surprised than me. But who knows, maybe this will be like that time somebody suggested we just send an atomic clock into space to unambiguously detect time dilation from relativity. A hacker can dream! I don’t want to pretend to be telling anyone how the universe works, because how the heck would I know. But maybe I can ask a few questions. Perhaps, strictly speaking, this is a disproof of Bell’s Theorem that is not superdeterminism. Technically a theory does not need to be correct to violate his particular formulation. It might actually be the case that this… Quantum Encraption is a local hidden variable theory that explains all the results of quantum mechanics.
–Dan
P.S. This approach absolutely does not predict a deterministic universe. Laser beams eventually decohere, just not immediately. Systems can absolutely have a mix of entropy sources, some good, some not. It takes very, very little actual universal entropy to create completely unpredictable chaos, and that’s kind of the point. The math still works just as predictably even with no actual randomness at all. Only if all entropy sources were deterministic at all scales could the universe be as well. And even then, the interaction of even extremely weak cryptosystems is itself strongly unpredictable over the scale of, I don’t know, billions of state exchanges. MD5 is weak, a billion rounds of MD5 is not. So there would be no way to predict or influence the state of the universe even given perfect determinism without just outright running the system.
[edit]P.P.S. “There is no outcome in quantum mechanics that cannot be handled by encraption, because if there was, you could communicate with it.” I’m not sure that’s correct but you know what passes the no communication theory really easily? No communication. Also, please, feel free to mail me privately at dan@doxpara.com or comment below.
Read My Lips: Let’s Kill 0Day
0day is cool. Killing 0day, sight unseen, at scale — that’s cooler.
If you agree with me, you might be my kind of defender, and the upcoming O’Reilly Security Conference(s) might be your kind of cons.
Don’t get me wrong. Offense is critical. Defense without Offense is after all just Compliance. But Defense could use a home. The Blue Team does not always have to be the away team.
So for quite some time, I’ve been asking Tim O’Reilly to throw a highly technical defensive security event. Well, be careful what you wish for. I actually keynoted his Velocity event with Zane Lackey a while back, and was struck by the openness of the environment, and the technical competence of the attendees. This is a thing that would be good for Defense, and so I’ve taken the rare step of actually joining the Program Committee for this one, CFP’s for NYC & Amsterdam are still open (but not for much longer!). How would you know if this is your sort of party?
NIST’s SAMATE project has been assembling this enormous collection of minimized vulnerability cases. They’re just trying to feed static analyzers, but if you’re filled with ideas of what else is possible with these terabytes of goodies – this is your con.
Researchers at Stanford instrumented the IDE’s of students, and watched how early failures predicted later ones. Can we predict the future authorship of security vulnerabilities? In what ways do languages themselves predict failures, independent of authors? If this interests you, this is your con.
If you’re in operations, don’t feel left out. You’re actually under attack, and you’re actively doing things to keep the lights on. We want to know how you’re fighting off the hordes.
We live in a golden age of compilers actually trying to help us (this was not always the case). Technologies like Address Sanitizer, Undefined Behavior Sanitizer, Stack Protection / /GS along with the Microsoft universe of Control Flow Guard and the post-Boehm-ish MemGC suggest a future of much faster bug discovery and much better runtime protections. Think you’ve got better? Think you can measure better? Cool, show us.
Or show us we’re wrong. Offensive researchers, there are better places for you to demonstrate the TLS attack of the hour, but if you haven’t noticed, a lot of defensive techniques have gotten a “free pass”, E for effort, that sort of thing. There’s a reason we call ‘em sandboxes; they’re things kids step into and out of pretty freely. Mitigations not living up to their hype? Security technologies actually hosting insecurity? Talk to a bunch of people who’d care.
We’re not going to fix the world just by blowing things up. Come, show us your most devious hacks, let’s redefine how we’re going to defend and fix the Internet.
The Cryptographically Provable Con Man
It’s not actually surprising that somebody would claim to be the creator of Bitcoin. Whoever “Satoshi Nakamoto” is, is worth several hundred million dollars. What is surprising is that credible people were backing Craig Wright’s increasingly bizarre claims. I could speculate why, or I could just ask. So I mailed Gavin Andresen, Chief Scientist of the Bitcoin Foundation, “What the heck?”:
What is going on here?
There’s clear unambiguous cryptographic evidence of fraud and you’re lending credibility to the idea that a public key operation could should or must remain private?
He replied as follows, quoted with permission:
Yeah, what the heck?
I was as surprised by the ‘proof’ as anyone, and don’t yet know exactly what is going on.
It was a mistake to agree to publish my post before I saw his– I assumed his post would simply be a signed message anybody could easily verify.
And it was probably a mistake to even start to play the Find Satoshi game, but I DO feel grateful to Satoshi.
If I’m lending credibility to the idea that a public key operation should remain private, that is entirely accidental. OF COURSE he should just publish a signed message or (equivalently) move some btc through the key associated with an early block.
Feel free to quote or republish this email.
Good on Gavin for his entirely reasonable reaction to this genuinely strange situation.
Craig Wright seems to be doubling down on his fraud, again, and I don’t care. The guy took an old Satoshi signature from 2009 and pretended it was fresh and new and applied to Sartre. It’s like Wright took the final page of a signed contract and stapled it to something else, then proclaimed to the world “See? I signed it!”.
That’s not how it works.
Say what you will about Bitcoin, it’s given us the world’s first cryptographically provable con artist. Scammers always have more to say, but all that matters now is math. He can actually sign “Craig Wright is Satoshi Nakamoto” with Satoshi’s keys, openly and publicly. Or he can’t, because he doesn’t have those keys, because he’s not actually Satoshi.
Validating Satoshi (Or Not)
SUMMARY:
- Yes, this is a scam. Not maybe. Not possibly.
- Wright is pretending he has Satoshi’s signature on Sartre’s writing. That would mean he has the private key, and is likely to be Satoshi. What he actually has is Satoshi’s signature on parts of the public Blockchain, which of course means he doesn’t need the private key and he doesn’t need to be Satoshi. He just needs to make you think Satoshi signed something else besides the Blockchain — like Sartre. He doesn’t publish Sartre. He publishes 14% of one document. He then shows you a hash that’s supposed to summarize the entire document. This is a lie. It’s a hash extracted from the Blockchain itself. Ryan Castellucci (my engineer at White Ops and master of Bitcoin Fu) put an extractor here. Of course the Blockchain is totally public and of course has signatures from Satoshi, so Wright being able to lift a signature from here isn’t surprising at all.
- He probably would have gotten away with it if the signature itself wasn’t googlable by Redditors.
- I think Gavin et al are victims of another scam, and Wright’s done classic misdirection by generating different scams for different audiences.
===
UPDATE: This signature does actually validate, you just have to use a different version of OpenSSL than I did originally.

Of course, if this is the signature that already went out with that block, it doesn’t matter. So I’m looking into that right now.
Update 2:
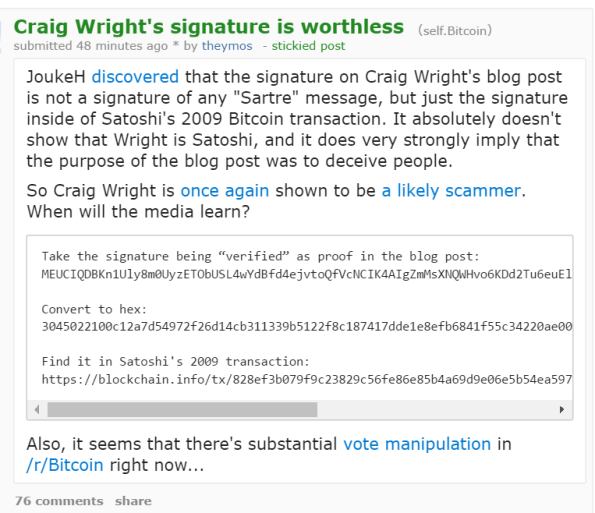
OK, yes, this is intentional scammery. This is the 2009 transaction. See this:

And then, that hex is of course this hex, as in the zip below:

Of course that’s exactly what Uptrenda on Reddit posted. Gotta give Wright very small props, that’s a mildly clever replay attack, foiled by total lack of QA.
====
So Craig Wright is claiming to be Satoshi, and importantly, Gavin Andreson believes him. I say importantly because normally I wouldn’t even give this document a second thought, it’s obviously scam style. But Gavin. Yet, the procedure that’s supposed to prove Dr. Wright is Satoshi is aggressively, almost-but-not-quite maliciously resistant to actual validation. OK, anyone can take screenshots of their terminal, but sha256sums of everything but the one file you actually would like a hash of? More importantly, lots of discussion of how cryptography works, but not why we should consider this particular public key interesting.
But it could actually be interesting. This public key claimed is indeed from a very early block, which was the constraint I myself declared.
But for those with an open mind, moving a few chunks of the so-called “bitcoin billion” should be proof enough, says Dan Kaminsky, a well-known security researcher with a history of bitcoin analysis. Even the theory that Wright might have somehow hacked Nakamoto’s computer hardly discounts that proof, Kaminsky argues. “Every computer can be hacked. But if he hacked Satoshi, then this guy knew who the real Satoshi was, and that’s more than what the rest of us can say,” Kaminsky points out. “If Wright does a transaction with one of these keys, he’s done something no other wannabe-Satoshi has done, and we should recognize that.”
OK, it’s not a key attached to the Bitcoin billion, but Block 9 is close enough for me. The bigger issue is that I can’t actually get the process to yield a valid signature. I’ve gone over the data a few times, and the signature isn’t actually validating. I’m not going to read too much into this because Dr. Wright didn’t actually post an OpenSSL version, and who knows if something changed. But it is important to realize — anyone can claim a public key, that’s why they’re called public keys. The signature actually does need to validate and I haven’t gotten it to work.
I could have missed something, it’s pretty late. So here’s the binary blobs — nobody should have to try to hand transcribe and validate hex like this. If I had to speculate, it’s just some serious fat fingering, where the signature is actually across some other message (like that Sartre text we see 14% of). Alternate explanations have to be … unlikely.
UPDATE:
*facepalm*
“The Feds Have Let The Cyber World Burn. Let’s Put the Fires Out.”
I’ve made some comments regarding Apple vs. the FBI at Wired.
I Might Be Afraid Of This Ghost
CVE-2015-7547 is not actually the first bug found in glibc’s DNS implementation. A few people have privately asked me how this particular flaw compares to last year’s issue, dubbed “Ghost” by its finders at Qualys. Well, here’s a list of what that flaw could not exploit:
apache, cups, dovecot, gnupg, isc-dhcp, lighttpd, mariadb/mysql, nfs-utils, nginx, nodejs, openldap, openssh, postfix, proftpd, pure-ftpd, rsyslog, samba, sendmail, sysklogd, syslog-ng, tcp_wrappers, vsftpd, xinetd.
And here are the results from a few minutes of research on the new bug.
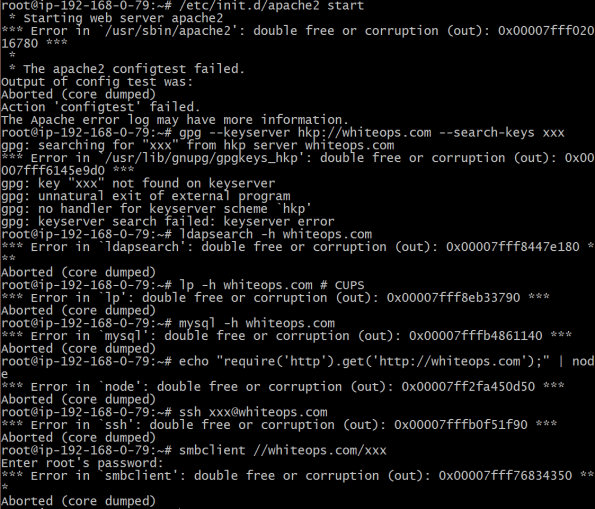
More is possible, but I think the point is made. The reason why the new flaw is significantly more virulent is that:
- This is a flaw in getaddrinfo(), which modern software actually uses nowadays for IPv6 compatibility, and
- Ghost was actually a really “fiddly” bug, in a way CVE-2015-7547 just isn’t.
As it happens, Qualys did a pretty great writeup of Ghost’s mitigating factors, so I’ll just let the experts speak for themselves:
- The gethostbyname*() functions are obsolete; with the advent of IPv6, recent applications use getaddrinfo() instead.
- Many programs, especially SUID binaries reachable locally, use gethostbyname() if, and only if, a preliminary call to inet_aton() fails. However, a subsequent call must also succeed (the “inet-aton” requirement) in order to reach the overflow: this is impossible, and such programs are therefore safe.
- Most of the other programs, especially servers reachable remotely, use gethostbyname() to perform forward-confirmed reverse DNS (FCrDNS, also known as full-circle reverse DNS) checks. These programs are generally safe, because the hostname passed to gethostbyname() has normally been pre-validated by DNS software:
- . “a string of labels each containing up to 63 8-bit octets, separated by dots, and with a maximum total of 255 octets.” This makes it impossible to satisfy the “1-KB” requirement.
- Actually, glibc’s DNS resolver can produce hostnames of up to (almost) 1025 characters (in case of bit-string labels, and special or non-printable characters). But this introduces backslashes (‘\\’) and makes it impossible to satisfy the “digits-and-dots” requirement.
And:
In order to reach the overflow at line 157, the hostname argument must meet the following requirements:
- Its first character must be a digit (line 127).
– Its last character must not be a dot (line 135).
– It must comprise only digits and dots (line 197) (we call this the “digits-and-dots” requirement).- It must be long enough to overflow the buffer. For example, the non-reentrant gethostbyname*() functions initially allocate their buffer with a call to malloc(1024) (the “1-KB” requirement).
- It must be successfully parsed as an IPv4 address by inet_aton() (line 143), or as an IPv6 address by inet_pton() (line 147). Upon careful analysis of these two functions, we can further refine this “inet-aton” requirement:
- It is impossible to successfully parse a “digits-and-dots” hostname as an IPv6 address with inet_pton() (‘:’ is forbidden). Hence it is impossible to reach the overflow with calls to gethostbyname2() or gethostbyname2_r() if the address family argument is AF_INET6.
- Conclusion: inet_aton() is the only option, and the hostname must have one of the following forms: “a.b.c.d”, “a.b.c”, “a.b”, or “a”, where a, b, c, d must be unsigned integers, at most 0xfffffffful, converted successfully (ie, no integer overflow) by strtoul() in decimal or octal (but not hexadecimal, because ‘x’ and ‘X’ are forbidden).
Like I said, fiddly, thus giving Qualys quite a bit of confidence regarding what was and wasn’t exploitable. By contrast, the constraints on CVE-2015-7547 are “IPv6 compatible getaddrinfo”. That ain’t much. The bug doesn’t even care about the payload, only how much is delivered and if it had to retry.
It’s also a much larger malicious payload we get to work with. Ghost was four bytes (not that that’s not enough, but still).
In Ghost’s defense, we know that flaw can traverse caches, requiring far less access for attackers. CVE-2015-7547 is weird enough that we’re just not sure.
A Skeleton Key of Unknown Strength
TL;DR: The glibc DNS bug (CVE-2015-7547) is unusually bad. Even Shellshock and Heartbleed tended to affect things we knew were on the network and knew we had to defend. This affects a universally used library (glibc) at a universally used protocol (DNS). Generic tools that we didn’t even know had network surface (sudo) are thus exposed, as is software written in programming languages designed explicitly to be safe. Who can exploit this vulnerability? We know unambiguously that an attacker directly on our networks can take over many systems running Linux. What we are unsure of is whether an attacker anywhere on the Internet is similarly empowered, given only the trivial capacity to cause our systems to look up addresses inside their malicious domains.
We’ve investigated the DNS lookup path, which requires the glibc exploit to survive traversing one of the millions of DNS caches dotted across the Internet. We’ve found that it is neither trivial to squeeze the glibc flaw through common name servers, nor is it trivial to prove such a feat is impossible. The vast majority of potentially affected systems require this attack path to function, and we just don’t know yet if it can. Our belief is that we’re likely to end up with attacks that work sometimes, and we’re probably going to end up hardening DNS caches against them with intent rather than accident. We’re likely not going to apply network level DNS length limits because that breaks things in catastrophic and hard to predict ways.
This is a very important bug to patch, and it is good we have some opportunity to do so.
It’s problematic that, a decade after the last DNS flaw that took a decade to fix, we have another one. It’s time we discover and deploy architectural mitigations for these sorts of flaws with more assurance than technologies like ASLR can provide. The hard truth is that if this code was written in JavaScript, it wouldn’t have been vulnerable. We can do better than that. We need to develop and fund the infrastructure, both technical and organizational, that defends and maintains the foundations of the global economy.
Click here if you’re a DNS expert and don’t need to be told how DNS works.
Click here if your interests are around security policy implications and not the specific technical flaw in question.
Update: Click here to learn how this issue compares to last year’s glibc DNS flaw, Ghost.
=====
Here is a galaxy map of the Internet. I helped the Opte project create this particular one.

And this galaxy is Linux – specifically, Ubuntu Linux, in a map by Thomi Richards, showing how each piece of software inside of it depends on each other piece.

There is a black hole at the center of this particular galaxy – the GNU C Standard Library, or glibc. And at this center, in this black hole, there is a flaw. More than your average or even extraordinary flaw, it’s affecting a shocking amount of code. How shocking?
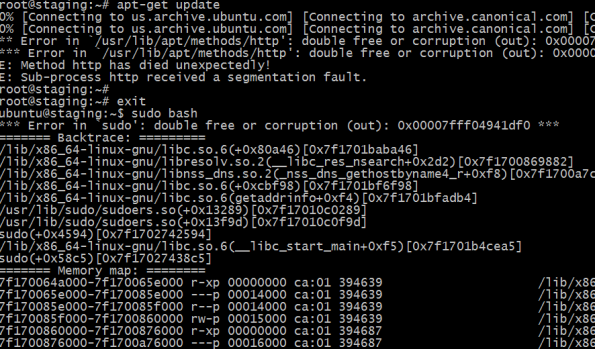
I’ve seen a lot of vulnerabilities, but not too many that create remote code execution in sudo. When DNS ain’t happy, ain’t nobody happy. Just how much trouble are we in?
We’re not quite sure.
Background
Most Internet software is built on top of Linux, and most Internet protocols are built on top of DNS. Recently, Redhat Linux and Google discovered some fairly serious flaws in the GNU C Library, used by Linux to (among many other things) connect to DNS to resolve names (like google.com) to IP addresses (like 8.8.8.8). The buggy code has been around for quite some time – since May 2008 – so it’s really worked its way across the globe. Full remote code execution has been demonstrated by Google, despite the usual battery of post-exploitation mitigations like ASLR, NX, and so on.
What we know unambiguously is that an attacker who can monitor DNS traffic between most (but not all) Linux clients, and a Domain Name Server, can achieve remote code execution independent of how well those clients are otherwise implemented. (Android is not affected.) That is a solid critical vulnerability by any normal standard.
Actionable Intelligence
Ranking exploits is silly. They’re not sports teams. But generally, what you can do is actually less important than who you have to be to do it. Bugs like Heartbleed, Shellshock, and even the recent Java Deserialization flaws ask very little of attackers – they have to be somewhere on a network that can reach their victims, maybe just anywhere on the Internet at large. By contrast, the unambiguous victims of glibc generally require their attackers to be close by.
You’re just going to have to believe me when I say that’s less of a constraint than you’d think, for many classes of attacker you’d actually worry about. More importantly though, the scale of software exposed to glibc is unusually substantial. For example:
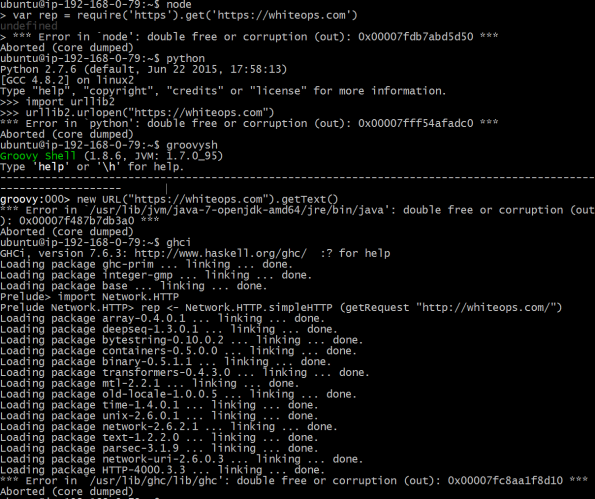
That’s JavaScript, Python, Java, and even Haskell blowing right up. Just because they’re “memory-safe” doesn’t mean their runtime libraries are, and glibc is the big one under Linux they all depend on. (Not that other C libraries should be presumed safe. Ahem.)
There’s a reason I’m saying this bug exposes Linux in general to risk. Even your paranoid solutions leak DNS – you can route everything over a VPN, but you’ve still got to discover where you’re routing it to, and that’s usually done with DNS. You can push everything over HTTPS, but what’s that text after the https://? It’s a DNS domain.
Importantly, the whole point of entire sets of defenses is that there’s an attacker on the network path. That guy just got a whole new set of toys, against a whole new set of devices. Everyone protects apache, who protects sudo?
So, independent of whatever else may be found, Florian, Fermin, Kevin, and everyone else at Redhat and Google did some tremendous work finding and repairing something genuinely nasty. Patch this bug with extreme prejudice. You’ll have to reboot everything, even if it doesn’t get worse.
It might get worse.
The Hierarchy
DNS is how this Internet (there were several previous attempts) achieves cross-organizational interoperability. It is literally the “identity” layer everything else builds upon; everybody can discover Google’s mail server, but only Google can change it. Only they have the delegated ownership rights for gmail.com and google.com. Those rights were delegated by Verisign, who owns .com, who themselves received that exclusive delegation from ICANN, the Internet Corporation for Assigned Names and Numbers.
The point is not to debate the particular trust model of DNS. The point is to recognize that it’s not just Google who can register domains; attackers can literally register badguy.com and host whatever they want there. If a DNS vulnerability could work through the DNS hierarchy, we would be in a whole new class of trouble, because it is just extraordinarily easy to compel code that does not trust you to retrieve arbitrary domains from anywhere in the DNS. You connect to a web server, it wants to put your domain in its logs, it’s going to look you up. You connect to a mail server, it wants to see if you’re a spammer, it’s going to look you up. You send someone an email, they reply. How does their email find you? Their systems are going to look you up.
It would be unfortunate if those lookups led to code execution.
Once, I gave a talk to two hundred software developers. I asked them, how many of you depend on DNS? Two hands go up. I then asked, how many of you expect a string of text like google.com to end up causing a connection to Google? 198 more hands. Strings containing domain names happen all over the place in software, in all sorts of otherwise safe programming languages. Far more often than not, those strings not only find their way to a DNS client, but specifically to the code embedded in the operating system (the one thing that knows where the local Domain Name Server is!). If that embedded code, glibc, can end up receiving from the local infrastructure traffic similar enough to what a full-on local attacker would deliver, we’re in a lot more trouble. Many more attackers can cause lookups to badguy.com, than might find themselves already on the network path to a target.
Domain Name Servers
Glibc is what is known as a “stub resolver”. It asks a question, it gets an answer, somebody else actually does most of the work running around the Internet bouncing through ICANN to Verisign to Google. These “somebody elses” are Domain Name Servers, also known as caching resolvers. DNS is an old protocol – it dates back to 1983 – and comes from a world where bandwidth was so constrained that every bit mattered, even during protocol design. (DNS got 16 bits in a place so TCP could get 32. “We were young, we needed the bits” was actually a thing.) These caching resolvers actually enforce a significant amount of rules upon what may or may not flow through the DNS. The proof of concept delivered by Google essentially delivers garbage bytes. That’s fine on the LAN, where there’s nothing getting in the way. But name servers can essentially be modeled as scrubbing firewalls – in most (never all) environments, traffic that is not protocol compliant is just not going to reach stubs like glibc. Certainly that Google Proof of Concept isn’t surviving any real world cache.
Does that mean nothing will? As of yet, we don’t actually know. According to Redhat:
A back of the envelope analysis shows that it should be possible to write correctly formed DNS responses with attacker controlled payloads that will penetrate a DNS cache hierarchy and therefore allow attackers to exploit machines behind such caches.
I’m just going to state outright: Nobody has gotten this glibc flaw to work through caches yet. So we just don’t know if that’s possible. Actual exploit chains are subject to what I call the MacGyver effect. For those unfamiliar, MacGyver was a 1980’s television show that showed a very creative tinkerer building bombs and other such things with tools like chocolate. The show inspired an entire generation of engineers, but did not lead to a significant number of lost limbs because there was always something non-obvious and missing that ultimately prevented anything from working. Exploit chains at this layer are just a lot more fragile than, say, corrupted memory. But we still go ahead and actually build working memory corruption exploits, because some things are just extraordinarily expensive to fix, and so we better be sure there’s unambiguously a problem here.
At the extreme end, there are discussions happening about widespread DNS filters across the Internet – certainly in front of sensitive networks. Redhat et al did some great work here, but we do need more than the back of the envelope. I’ve personally been investigating cache traversal variants of this attack. Here’s what I can report after a day.
Cache Attacks
Somewhat simplified, the attacks depend on:.
- A buffer being filled with about 2048 bytes of data from a DNS response
- The stub retrying, for whatever reason
- Two responses ultimately getting stacked into the same buffer, with over 2048 bytes from the wire
The flaw is linked to the fact that the stack has two outstanding requests at the same time – one for IPv4 addresses, and one for IPv6 addresses. Furthermore DNS can operate over both UDP and TCP, with the ability to upgrade from the former to the latter. There is error handling in DNS, but most errors and retries are handled by the caching resolver, not the stub. That means any weird errors just cause the (safer, more properly written) middlebox to handle the complexity, reducing degrees of freedom for hitting glibc.
Given that rough summary of the constraints, here’s what I can report. This CVE is easily the most difficult to scope bug I’ve ever worked on, despite it being in a domain I am intimately familiar with. The trivial defenses against cache traversal are easily bypassable; the obvious attacks that would generate cache traversal are trivially defeated. What we are left with is a morass of maybe’s, with the consequences being remarkably dire (even my bug did not yield direct code execution). Here’s what I can say at present time, with thanks to those who have been very generous with their advice behind the scenes.
- The attacks do not need to be garbage that could never survive a DNS cache, as they are in the Google PoC. It’s perfectly legal to have large A and AAAA responses that are both cache-compatible and corrupt client memory. I have this working well.
- The attacks do not require UDP or EDNS0. Traditional DNS has a 512 byte limit, notably less than the 2048 bytes required. Some people (including me) thought that since glibc doesn’t issue the EDNS0 request that declares a larger buffer, caching resolvers would not provide sufficient data to create the required failure state. Sure, if the attack was constrained to UDP as in the Google PoC. But not only does TCP exist, but we can set the tc “Truncation” bit to force an upgrade to the protocol with more bandwidth. This most certainly does traverse caches.
- There are ways of making the necessary retry occur, even through TCP. We’re still investigating them, as it’s a fundamental requirement for the attack to function. (No retry, no big write to small buf.)
Where I think we’re going to end up, around 24 (straight) hours of research in, is that some networks are going to be vulnerable to some cache traversal attacks sometimes, following the general rule of “attacks only get better”. That rule usually only applies to crypto vulns, but on this half-design half-implementation vuln, we get it here too. This is in contrast to the on-path attackers, who “just” need to figure out how to smash a 2016 stack and away they go. There’s a couple comments I’d like to make, which summarize down to “This may not get nasty in days to weeks, but months to years has me worried.”
- Low reliability attacks become high reliability in DNS, because you can just do a lot of them very quickly. Even without forcing an endpoint to hammer you through some API, name servers have all sorts of crazy corner cases where they blast you with traffic quickly, and stop only when you’ve gotten data successfully in their cache. Load causes all sorts of weird and wooly behavior in name servers, so proving something doesn’t work in the general case says literally nothing about edge case behavior.
- Low or no Time To Live (TTL) mean the attacker can disable DNS caching, eliminating some (but not nearly all) protections one might assume caching creates. That being said, not all name servers respect a zero TTL, or even should.
- If anything is going to stop actual cache traversing exploitability, it’s that you just have an absurd amount more timing and ordering control directly speaking to clients over TCP and UDP, than you do indirectly communicating with the client through a generally protocol enforcing cache. That doesn’t mean there won’t be situations where you can cajole the cache to do your bidding, even unreliably, but accidental defenses are where we’re at here.
- Those accidental defenses are not strong. They’re accidents, in the way DNS cache rules kept my own attacks from being discovered. Eventually we figured out we could do other things to get around those defenses and they just melted in seconds. The possibility that a magic nasty payload pushes a major namesever or whatever into some state that quickly and easily knocks stuff over, on the scale of months to years, is non-trivial.
- Stub resolvers are not just weak, they’re kind of designed to be that way. The whole point is you don’t need a lot of domain specific knowledge (no pun intended) to achieve resolution over DNS; instead you just ask a question and get an answer. Specifically, there’s a universe of DNS clients that don’t randomize ports (or even transaction id’s). You really don’t want random Internet hosts poking your clients spoofing your name servers. Protecting against spoofed traffic on the global Internet is difficult; preventing traffic spoofing from outside networks using internal addresses is on the edge of practicality.
Let’s talk about suggested mitigations, and then go into what we can learn policy-wise from this situation.
Length Limits Are Silly Mitigations
No other way to say it. Redhat might as well have suggested filtering all AAAA (IPv6) records – might actually be effective, as it happens, but it turns out security is not the only engineering requirement at play. DNS has had to engineer several mechanisms for sending more than 512 bytes, and not because it was a fun thing to do on a Saturday night. JavaScript is not the only thing that’s gotten bigger over the years; we are putting more and more in there and not just DNSSEC signatures either. What is worth noting is that IT, and even IT Security, has actually learned the very very hard way not to apply traditional firewalling approaches to DNS. Basically, as a foundational protocol it’s very far away from normal debugging interfaces. That means, when something goes wrong – like, somebody applied a length limit to DNS traffic who was not themselves a DNS engineer – there’s this sudden outage that nobody can trace for some absurd amount of time. By the time the problem gets traced…well, if you ever wondered why DNS doesn’t get filtered, that is why.
And ultimately, any DNS packet filter is a poor version of what you really want, which is an actual protocol enforcing scrubbing firewall, i.e. a name server that is not a stub, though it might be a forwarder (meaning it enforces all the rules and provides a cache, but doesn’t wander around the Internet resolving names). My expectations for mitigations, particularly as we actually start getting some real intelligence around cache traversing glibc attacks, are:
- We will put more intelligent resolvers on more devices, such that glibc is only talking to the local resolver not over the network, and
- Caching resolvers will learn how to specially handle the case of simultaneous A and AAAA requests. If we’re protected from traversing attacks it’s because the attacker just can’t play a lot of games between UDP and TCP and A and AAAA responses. As we learn more about when the attacks can traverse caches, we can intentionally work to make them not.
Local resolvers are popular anyway, because they mean there’s a DNS cache improving performance. A large number of embedded routers are already safe against the verified on-path attack scenario due to their use of dnsmasq, a common forwarding cache.
Note that technologies like DNSSEC are mostly orthogonal to this threat; the attacker can just send us signed responses that he in particular wants to break us. I say mostly because one mode of DNSSEC deployment involves the use of a local validating resolver; such resolvers are also DNS caches that insulate glibc from the outside world.
There is the interesting question of how to scan and detect nodes on your network with vulnerable versions of glibc. I’ve been worried for a while we’re only going to end up fixing the sorts of bugs that are aggressively trivial to detect, independent of their actual impact to our risk profiles. Short of actually intercepting traffic and injecting exploits I’m not sure what we can do here. Certainly one can look for simultaneous A and AAAA requests with identical source ports and no EDNS0, but that’s going to stay that way even post patch. Detecting what on our networks still needs to get patched (especially when ultimately this sort of platform failure infests the smallest of devices) is certain to become a priority – even if we end up making it easier for attackers to detect our faults as well.
If you’re looking for actual exploit attempts, don’t just look for large DNS packets. UDP attacks will actually be fragmented (normal IP packets cannot carry 2048 bytes) and you might forget DNS can be carried over TCP. And again, large DNS replies are not necessarily malicious.
And thus, we end up at a good transition point to discuss security policy. What do we learn from this situation?
The Fifty Thousand Foot View
Patch this bug. You’ll have to reboot your servers. It will be somewhat disruptive. Patch this bug now, before the cache traversing attacks are discovered, because even the on-path attacks are concerning enough. Patch. And if patching is not a thing you know how to do, automatic patching needs to be something you demand from the infrastructure you deploy on your network. If it might not be safe in six months, why are you paying for it today?
It’s important to realize that while this bug was just discovered, it’s not actually new. CVE-2015-7547 has been around for eight years. Literally, six weeks before I unveiled my own grand fix to DNS (July 2008), this catastrophic code was committed.
Nobody noticed.
The timing is a bit troublesome, but let’s be realistic: there’s only so many months to go around. The real issue is it took almost a decade to fix this new issue, right after it took a decade to fix my old one (DJB didn’t quite identify the bug, but he absolutely called the fix). The Internet is not less important to global commerce than it was in 2008. Hacker latency continues to be a real problem.
What maybe has changed over the years is the strangely increasing amount of talk about how the Internet is perhaps too secure. I don’t believe that, and I don’t believe anyone in business (or even with a credit card) does either. But the discussion on cybersecurity seems dominated by the necessity of insecurity. Did anyone know about this flaw earlier? There’s absolutely no way to tell. We can only know we need to be finding these bugs faster, understanding these issues better, and fixing them more comprehensively.
We need to not be finding bugs like this, eight years from now, again.
(There were clear public signs of impending public discovery of this flaw, so do not take my words as any form of criticism for the release schedule of this CVE.)
My concerns are not merely organizational. I do think we need to start investing significantly more in mitigation technologies that operate before memory corruption has occurred. ASLR, NX, Control Flow Guard – all of these technologies are greatly impressive, at showing us who our greatly impressive hackers are. They’re not actually stopping code execution from being possible. They’re just not.
Somewhere between base arithmetic and x86 is a sandbox people can’t just walk in and out of. To put it bluntly, if this code had been written in JavaScript – yes, really – it wouldn’t have been vulnerable. Even if this network exposed code remained in C, and was just compiled to JavaScript via Emscripten, it still would not have been vulnerable. Efficiently microsandboxing individual codepaths is a thing we should start exploring. What can we do to the software we deploy, at what cost, to actually make exploitation of software flaws actually impossible, as opposed to merely difficult?
It is unlikely this is the only platform threat, or even the only threat in glibc. With the Internet of Things spreading extraordinarily, perhaps it’s time to be less concerned about being able to spy on every last phone call and more concerned about how we can make sure innovators have better environments to build upon. I’m not merely talking about the rather “frothy” software stacks adorning the Internet of Things, with Bluetooth and custom TCP/IP and so on. I’m talking about maintainability. When we find problems — and we will — can we fix them? This is a problem that took Android too long to start seriously addressing, but they’re not the only ones. A network where devices eventually become existential threats is a network that eventually ceases to exist. What do we do for platforms to guarantee that attack windows close? What do we do for consumers and purchasing agents so they can differentiate that which has a maintenance warranty, and that which does not?
Are there insurance structures that could pay out, when a glibc level patch needs to be rolled out?
There’s a level of maturity that can be brought to the table, and I think should. There are a lot of unanswered questions about the scope of this flaw, and many others, that perhaps neither vendors nor volunteer researchers are in the best position to answer. We can do better building the secure platforms of the future. Let’s start here.
Defcon 23: Let’s End Clickjacking
So, my Defcon talk, ultimately about ending clickjacking by design.
TL:DR: The web is actually fantastic, and one of the cool things about it is the ability for mutually distrusting entities to share the same browser, or even the same web page. What’s not so cool is that embedded content has no idea what’s actually being presented to the user — Paypal could have a box that says “Want to spend $1000” and somebody could shove an icon on top of that saying “$1.00” and nobody could tell, least of all Paypal.
I want to fix that, and all other Clickjacking attacks. Generally the suggested solution involves pixel scraping, i.e. comparing what was supposed to be drawn to what actually was. But it’s way too slow to do that generically. Browsers don’t actually know what pixels are ultimately drawn normally; they just send a bunch of stuff to the GPU and say “you figure it out”.
But they do know what they send to the GPU. Web pages are like transparencies, one stacked over the next. So, I’ve made a little thing called IronFrame, that works sort of like Jenga: We take the layer from the bottom, and put it on top. Instead of auditing, we make it so the only thing that could be rendered, is what should be rendered. It works remarkably well, even just now. There’s a lot more work to do before web browsers can really use this, but let’s fix the web!
Oh, also, here’s a CPU monitor written in JavaScript that works cross domain.
Safe Computing In An Unsafe World: Die Zeit Interview
So some of the more fun bugs involve one team saying, “Heh, we don’t need to validate input, we just pass data through to the next layer.” And the the next team is like, “Heh, we don’t need to validate input, it’s already clean by the time it reaches us.” The fun comes when you put these teams in the same room. (Bring the popcorn, but be discreet!)
Policy and Technology have some shared issues, that sometimes they want each other to solve. Meanwhile, things stay on fire.
I talked about some of our challenges in Infosec with Die Zeit recently. Germany got hit pretty bad recently and there’s some soul searching. I’ll let the interview mostly speak for itself, but I would like to clarify two things:
1) Microsoft’s SDL (Security Development Lifecycle) deserves more credit. It clearly yields more secure code. But getting past code, into systems, networks, relationships, environments — there’s a scale of security that society needs, which technology hasn’t achieved yet.
2) I’m not at all advocating military response to cyber attacks. That would be awful. But there’s not some magic Get Out Of War free card just because something came over the Internet. For all the talk of regulating non-state actors, it’s actually the states that can potentially completely overwhelm any potential technological defense. Their only constraints are a) fear of getting caught, b) fear of damaging economic interests, and c) fear of causing a war. I have doubts as to how strong those fears are, or remain. See, they’re called externalities for a reason…
(Note: This interview was translated into German, and then back into English. So, if I sound a little weird, that’s why.)

(Headline) „No one knows how to make a computer safe.”
(Subheading) The American computer security specialist Dan Kaminsky talks about the cyber-attack on the German Bundestag: In an age of hacker wars, diplomacy is a stronger weapon than technology.
AMENDED VERSION
Dan Kaminsky (https://dankaminsky.com/bio/) is one of the most well-known hacker- and IT security specialists in the United States. He made a name for himself with the discovery of severe security holes on the Internet and in computer systems of large corporations. In 2008, he located a basic error in the DNS, (http://www.wired.com/2008/07/kaminsky-on-how/), the telephone book of the Internet, and coordinated a worldwide repair. Nowadays, he works as a “chief scientist” at the New York computer security firm White Ops. (http://www.whiteops.com).
Questions asked by Thomas Fischermann
ZEIT Online: After the cyber attack on the German Bundestag, there has been a lot of criticism against the IT manager. (http://www.zeit.de/digital/datenschutz/2015-06/hackerangriff-bundestag-kritik).
Are the Germans sloppy when it comes to computer security?
Dan Kaminsky: No one should be surprised if a cyber attack succeeds somewhere. Everything can be hacked. I assume that all large companies are confronted somehow with hackers in their systems, and in national systems, successful intrusions have increased. The United States, e.g., have recently lost sensitive data of people with “top security” access to state secrets to Chinese hackers. (http://www.reuters.com/article/2015/06/15/us-cybersecurity-usa-exposure-idUSKBN0OV0CC20150615)
ZEIT Online: Due to secret services and super hackers employed by the government who are using the Internet recently?
Kaminsky: I’ll share a business secret with you: Hacking is very simple. Even teenagers can do that. And some of the most sensational computer break-ins in history are standard in technical terms – e.g., the attack on the Universal Sony Pictures in the last year where Barack Obama publically blamed North Korea for. (http://www.zeit.de/2014/53/hackerangriff-sony-nordkorea-obama). Three or four engineers manage that in three to four months.
ZEIT Online: It has been stated over and over again that some hacker attacks carry the “signature” of large competent state institutions.
Kaminsky: Sometimes it is true, sometimes it is not. Of course, state institutions can work better, with less error rates, permanently and more unnoticed. And they can attack very difficult destinations: e.g., nuclear power plants, technical infrastructures. They can prepare future cyber-attacks and could turn off the power of an entire city in case of an event of war.
ZEIT Online: But once more: Could we not have protected the computer of the German Bundestag better?
Kaminsky: There is a very old race among hackers between attackers and defenders. Nowadays, attackers have a lot of possibilities while defenders only have a few. At the moment, no one knows how to make a computer really safe.
ZEIT Online: That does not sound optimistic.
Kaminsky: The situation can change. All great technological developments have been unsafe in the beginning, just think of the rail, automobiles and aircrafts. The most important thing in the beginning is that they work, after that they get safer. We have been working on the security of the Internet and the computer systems for the last 15 years…
ZEIT Online: How is it going?
Kaminsky: There is a whole movement for example that is looking for new programming methods in order to eliminate the gateways for hackers. In my opinion, the “Langsec” approach is very interesting (http://www.upstandinghackers.com/langsec), with which you are looking for a kind of a binding grammar for computer programs and data formats that make everything safe. If you follow the rules, it should be hard for a programmer to produce that kind of errors that would be used by hostile hackers later on. When a system executes a program in the future or when a software needs to process a data record, it will be checked precisely to see if all rules where followed – as if a grammar teacher would check them.
ZEIT Online: That still sounds very theoretical…
Kaminsky: It is a new technology, it is still under development. In the end it will not only be possible to write a secure software, but also to have it happen in a natural way without any special effort, and it shall be cheap.
ZEIT Online: Which other approaches do you consider promising?
Kaminsky: Ongoing safety tests for computer networks are becoming more widespread: Firms and institutions pay hackers to permanently break-in in order to find holes and close them. Nowadays, this happens sporadically or in large intervals, but in the future we will need more of those “friendly” hackers. Third, there is a totally new generation of anti-hacker software in progress. Their task is not to prevent break-ins – because they will happen anyway – but to observe the intruders very well. This way we can assess better who the hackers are and we can prevent them from gaining access over days or weeks.
ZEIT Online: Nevertheless, those are still future scenarios. What can we do today if we are already in possession of important data? Go offline?
Kaminsky: No one will go offline. That is simply too inefficient. Even today you can already store data in a way that they are not completely gone after a successful hacker attack. You split them. Does a computer user really ever need to have access to all the documents in the whole system? Does the user need so much system band width that he can download masses of documents?
ZEIT Online: A famous case for this is the US Secret Service that lost thousands of documents to Edward Snowden. There are also a lot of hackers though who work for the NSA in order to break in other computer systems …
Kaminsky: … yeah, and that is poison for the security of the net. The NSA and a lot of other secret services say nowadays: We want to defend our computers – and attack the others. Most of the time, they decide to attack and make the Internet even more unsafe for everyone.
ZEIT Online: DO you have an example for this?
Kaminsky: American secret services have known for more than a decade that a spy software can be saved on the operating system of computer hard disks.
(http://www.geek.com/apps/nsa-malware-found-hiding-in-hard-drives-for-almost-20-years-1615949/, http://www.kaspersky.com/about/news/virus/2015/Equation-Group-The-Crown-Creator-of-Cyber-Espionage). Instead of getting rid of those security holes, they have been actively using it for themselves over the years… The spyware was open for the secret services – who have been using it for a number of malwares that have been discovered recently– and for everyone who has discovered those holes as well.
ZEIT Online: Can you change such a behavior?
Kaminsky: Yes, economically. Nowadays, spying authorities draw their right to exist from being able to get information from other people’s computer. If they made the Internet safer, they would hardly be rewarded for that…
ZEIT Online: A whole industry is taking care of the security of the net as well: Sellers of anti-virus and other protection programs.
Kaminsky: Nowadays, we spend a lot of money on security programs. But we do not even know if the computers that are protected in that way are really the ones who get hacked less often. We do not have any good empirical data and no controlled study about that.
ZEIT Online: Why does no one take such studies?
Kaminsky: This is obviously a market failure. The market does not offer services that would be urgently needed for increased safety in computer networks. A classical case in which governments could make themselves useful – the state. By the way, the state could contribute something else: deterrence
ZEIT Online: Pardon?
Kaminsky: In terms of computer security, we still blame the victims themselves most of the time: You have been hacked, how dumb! But when it comes to national hacker attacks that could lead to cyber wars this way of thinking is not appropriate. If someone dropped bombs over a city, no one’s first reaction would be: How dumb of you to not having thought about defensive missiles!
ZEIT Online: How should the answer look like then?
Kaminsky: Usually nation states are good in coming up with collective punishments: diplomatic reactions, economic sanctions or even acts of war. It is important that the nation states discuss with each other about what would be an adequate level of national hacker attacks and what would be too much. We have established that kind of rules for conventional wars but not for hacker attacks and cyber war. For a long time they had been considered as dangerous, but that has changed. You want to live in a cyber war zone as little as you want to live in a conventional war zone!
ZEIT Online: To be prepared for counterstrikes you first of all have to know the attacker. We still do not know the ones who were responsible for the German Bundestag hack…
Kaminsky: Yeah, sometimes you do not know who is attacking you. In the Internet there are not that many borders or geographical entities, and attackers can even veil their background. In order to really solve this problem, you would have to change the architecture of the Internet.
ZEIT Online: You had to?
Kaminsky: … and then there is still the question: Would it be really better for us, economically wise, than the leading communication technologies Minitel from France or America Online? Were our lives better when network connections were still horrible expensive? And is a new kind of net even possible when well appointed criminals or nation states could find new ways for manipulation anyway? The „attribution problem“ with cyber attacks stays serious and there are no obvious solutions. There are a lot of solutions though that are even worse than the problem itself.
Questions were asked by Thomas Fischermann (@strandreporter, @zeitbomber)
Talking with Stewart Baker
So I went ahead and did a podcast with Stewart Baker, former general counsel for the NSA and actually somebody I have a decent amount of respect for (Google set me up with him during the SOPA debate, he understood everything I had to say, and he really applied some critical pressure publicly and behind the scenes to shut that mess down). Doesn’t mean I agree with the guy on everything. I told him in no uncertain terms we had some disagreements regarding backdoors. and if he asked me about them I’d say as such. He was completely OK with this, and in today’s echo-chamber loving society that’s a real outlier. The debate is a ways in, and starts around here.
You can get the audio (and a summary) here but as usual I’ve had the event transcribed. Enjoy!
Steptoe Cyberlaw Podcast-070
Stewart: Welcome to episode 70 of the Steptoe Cyberlaw Podcast brought to you by Steptoe & Johnson; thank you for joining us. We’re lawyers talking about technology, security, privacy in government and I’m joined today by our guest commentator, Dan Kaminsky, who is the Chief Scientist at WhiteOps, the man who found and fixed a major and very troubling flaw in the DNS system and my unlikely ally in the fight against SOPA because of its impact on DNS security. Welcome, Dan.
Dan: It’s good to be here.
Stewart: All right; and Michael Vatis, formerly with the FBI and the Justice Department, now a partner in in Steptoe’s New York office. Michael, I’m glad to have you back, and I guess to be back with you on the podcast.
Michael: It’s good to have a voice that isn’t as hoarse as mine was last week.
Stewart: Yeah, that’s right, but you know, you can usually count on Michael to know the law – this is a valuable thing in a legal podcast – and Jason Weinstein who took over last week in a coup in the Cyberlaw podcast and ran it and interviewed our guest, Jason Brown from the Secret Service. Jason is formerly with the Justice Department where he oversaw criminal computer crime, prosecutions, among other things, and is now doing criminal and civil litigation at Steptoe.
I’m Stewart Baker, formerly with NSA and DHS, the record holder for returning to Steptoe to practice law more times than any other lawyer, so let’s get started. For old time’s sake we ought to do one more, one last hopefully, this week in NSA. The USA Freedom Bill was passed, was debated, not amended after efforts; passed, signed and is in effect, and the government is busy cleaning up the mess from the 48/72 hours of expiration of the original 215 and other sunsetted provisions.
So USA Freedom; now that it’s taken effect I guess it’s worth asking what does it do. It gets rid of bulk collection across the board really. It says, “No, you will not go get stuff just because you need it, and won’t be able to get it later if you can’t get it from the guy who holds it, you’re not going to get it.” It does that for a pen trap, it does that for Section 215, the subpoena program, and it most famously gets rid of the bulk collection program that NSA was running and that Snowden leaked in his first and apparently only successful effort to influence US policy.
[Helping] who are supposed to be basically Al Qaeda’s lawyers – that’s editorializing; just a bit – they’re supposed to stand for freedom and against actually gathering intelligence on Al Qaeda, so it’s pretty close. And we’ve never given the Mafia its own lawyers in wiretap cases before the wiretap is carried out, but we’re going to do that for –
Dan: To be fair you were [just] wiretapping the Mafia at the time.
Stewart: Oh, absolutely. Well, the NSA never really had much interest in the Mafia but with Title 3 yeah; you went in and you said, “I want a Title 3 order” and you got it if you met the standard, in the view of judge, and there were no additional lawyers appointed to argue against giving you access to the Mafia’s communications. And Michael, you looked at it as well – I’d say those were the two big changes – there are some transparency issues and other things – anything that strikes you as significant out of this?
Michael: I think the only other thing I would mention is the restrictions on NSLs where you now need to have specific selection terms for NSLs as well, not just for 215 orders.
Stewart: Yeah, really the house just went through and said, ”Tell us what capabilities could be used to gather international security agencies’ information and we will impose this specific selection term, requirement, on it.” That is really the main change probably for ordinary uses of 215 as though it were a criminal subpoena. Not that much change. I think the notion of relevance has probably always carried some notion that there is a point at which it gathered too much and the courts would have said, “That’s too much.”
Michael: going in that, okay, Telecoms already retain all this stuff for 18 months for billing purpose, and they’re required to by FCC regulation, but I think as we’ve discussed before, they’re not really required to retain all the stuff that NSA has been getting under bulk retention program, especially now that people have unlimited calling plans, Telecoms don’t need to retain information about every number call because it doesn’t matter for billing purposes.
So I think, going forward, we’ll probably hear from NSA that they’re not getting all the information they need, so I don’t think this issue is going to go away forever now. I think we’ll be hearing complaints and having some desire by the Administration to impose some sort of data retention requirements on Telecoms, and then they’ll be a real fight.
Stewart: That will be a fight. Yeah, I have said recently that, sure, this new approach can be as effective as the old approach if you think that going to the library is an adequate substitute for using Google. They won’t be able to do a lot of the searching that they could do and they won’t have as much data. But on the upside there are widespread rumors that the database never included many smaller carriers, never included mobile data probably because of difficulties separating out location data from the things that they wanted to look at.
So privacy concerns have already sort of half crippled the program and it also seems to me you have to be a remarkably stupid terrorist to think that it’s a good idea to call home using a phone that operates in the United States. People will use call of duty or something to communicate.
All right, the New York Times has one of its dumber efforts to create a scandal where there is none – it was written by Charlie Savage and criticized “Lawfare” by Ben Wittes and Charlie, who probably values his reputation in National Security circles somewhat, writes a really slashing response to Ben Wittes, but I think, frankly, Ben has the better of the argument.
The story says “Without public notice or debate the Obama Administration has expanded NSAs warrant with surveillance of American’s international internet traffic to search for evidence of malicious computer hacking” according to some documents obtained from Snowden. It turns out, if I understand this right, that what NSA was looking for in that surveillance, which is a 702 surveillance, was malware signatures and other indicia that somebody was hacking Americans, so they collected or proposed to collect the incoming communications from the hackers, and then to see what was exfiltrated by the hackers.
In what universe would you describe that as American’s international internet traffic? I don’t think when somebody’s hacking me or stealing my stuff, that that’s my traffic. That’s his traffic, and to lead off with that framing of the issue it’s clearly baiting somebody for an attempted scandal, but a complete misrepresentation of what was being done.
Dan: I think one of the issues is there’s a real feeling, “What are you going to do with that data?” Are you going to report it? Are you going to stop malware? Are you going to hunt someone down?
Stewart: All of it.
Dan: Where is the – really?
Stewart: Yeah.
Dan: Because there’s a lot of doubt.
Stewart: Yeah; I actually think that the FBI regularly – this was a program really to support the FBI in its mission – and the FBI has a program that’s remarkably successful in the sense that people are quite surprised when they show up, to go to folks who have been compromised to say, “By the way, you’re poned,” and most of the time when they do that some people say, “What? Huh?” This is where some of that information almost certainly comes from.
Dan: The reality is, everyone always says, “I can’t believe Sony got hacked,” and many of us actually in the field go, “Of course we can believe it.” Sony got hacked because everybody’s hacked somewhere.
Stewart: Yes, absolutely.
Dan: There’s a real need to do something about this on a larger scale. There is just such a lack of trust going on out there.
Stewart: Oh yeah.
Dan: And it’s not without reason.
Stewart: Yeah; Jason, any thoughts about the FBIs role in this?
Jason: Yeah. I think that, as you said, the FBI does a very effective job at knocking on doors or either pushing out information generally through alerts about new malware signatures or knocking on doors to tell particular victims they’ve been hacked. They don’t have to tell them how they know or what the source of the information is, but the information is still valuable.
I thought to the extent that this is one of those things under 702, where I think a reasonable person will look at this and be appreciative of the fact that the government was doing this, not critical. And as you said, the notion that this is sort of stolen internet traffic from Americans is characterized as surveillance of American’s traffic, is a little bit nonsensical.
Stewart: So without beating up Charlie Savage – I like him, he deserves it on this one – but he’s actually usually reasonably careful. The MasterCard settlement or the failed MasterCard settlement in the Target case, Jason, can you bring us up to date on that and tell us what lessons we should learn from it?
Jason: There have been so many high profile breaches in the last 18 months people may not remember Target, which of course was breached in the holiday season of 2013. MasterCard, as credit card companies often do, try to negotiate a settlement on behalf of all of their issuing banks with Target to pay damages for losses suffered as a result of the breach. In April MasterCard negotiated a proposed settlement with Target that would require Target to pay about $19 million to the various financial institutions that had to replace cards and cover for all losses and things of that nature.
But three of the largest banks, in fact I think the three largest MasterCard issuing banks, Citi Group, Capital One and JP Morgan Chase, all said no, and indicated they would not support the settlement and scuttled it because they thought $19 million was too small to cover the losses. There are trade groups for the banks and credit unions that say that between the Target and Home Depot breaches combined there were about $350 million in costs incurred by the financial institutions to reissue cards and cover losses, and so even if you factor out the Home Depot portion of that $19 million, it’s a pretty small number.
So Target has to go back to the drawing board, as does MasterCard to figure out if there’s a settlement or if the litigation is going to continue. And there’s also a proposed class action ongoing in Minnesota involving some smaller banks and credit unions as well. It would only cost them $10 million to settle the consumer class action, but the bigger exposure is here with the financial institution – Michael made reference last week to some press in which some commentator suggested the class actions from data breaches were on the wane – and we both are of the view that that’s just wrong.
There may be some decrease in privacy related class actions related to misuse of private information by providers, but when it comes to data breaches involving retailers and credit card information, I think not only are the consumer class actions not going anywhere, but the class actions involving the financial institutions are definitely not going anywhere. Standing is not an issue at all. It’s pretty easy for these planners to demonstrate that they suffered some kind of injury; they’re the ones covering the losses and reissuing the cards, and depending on the size of the breach the damages can be quite extensive. I think it’s a sign of the times that in these big breaches you’ll find banks that are insisting on a much bigger pound of flesh from the victims.
Stewart: Yeah, I think you’re right about that. The settlements, as I saw when I did a quick study of settlements for consumers, are running between 50 cents and two bucks per exposure, which is not a lot, and the banks’ expenses for reissuing cards are more like 50 bucks per victim. But it’s also true that many of these cards are never going to be used; many of these numbers are never going to be used, and so spending 50 bucks for every one of them to reissue the cards, at considerable cost to the consumers as well, might be an overreaction, and I wouldn’t be surprised if that were an argument.
Dan: So my way of looking at this is from the perspective of deterrence. Is $19 million enough of a cost to Target to cause them to change their behavior and really divest – it’s going to extraordinarily expense to migrate our payment system to the reality, which is we have online verification. We can use better technologies. They exist. There’s a dozen ways of doing it that don’t lead to a password to your money all over the world. This is ridiculous.
Stewart: It is.
Dan: I’m just going to say the big banks have a point; $19 million is –
Stewart: Doesn’t seem like a lot.
Dan: to say, “We really need to invest in this; this never needs to happen again,” and I’m not saying 350 is the right number but I’ve got to agree, 19 is not.
Stewart: All right then. Okay, speaking of everybody being hacked, everybody includes the Office of Personnel Management.
Dan: Yeah.
Stewart: My first background investigation and it was quite amusing because the government, in order to protect privacy, blacked out the names of all the investigators who I wouldn’t have known from Adam, but left in all my friends’ names as they’re talking about my drug use, or not.
Dan: Alleged.
Stewart: Exactly; no, they were all stand up guys for me, but there is a lot of stuff in there that could be used for improper purposes and it’s perfectly clear that if the Chinese stole this, stole the Anthem records, the health records, they are living the civil libertarian’s nightmare about what NSA is doing. They’re actually building a database about every American in the country.
Dan: Yeah, a little awkward, isn’t it?
Stewart: Well, annoying at least; yes. Jason, I don’t know if you’ve got any thoughts about how OPN responds to this? They apparently didn’t exactly cover themselves with glory in responding to an IG report from last year saying, “Your system sucks so bad you ought to turn them off.”
Jason: Well, first of all as your lawyer I should say that your alleged drug use was outside the limitations period of any federal or state government that I’m aware of, so no one should come after you. I thought it was interesting that they were offering credit monitoring, given that the hack has been attributed to China, which I don’t think is having any money issues and is going to steal my credit card information.
I’m pretty sure that the victims include the three of us so I’m looking forward to getting that free 18 months of credit monitoring. I guess they’ve held out the possibility that the theft was for profit as opposed to for espionage purposes, and the possibility that the Chinese actors are not state sponsored actors, but that seems kind of nonsensical to me. And I think that, as you said, as you both said, that the Chinese are building the very database on us that Americans fear that the United States was building.
Stewart: Yeah, and I agree with you that credit monitoring is a sort of lame and bureaucratic response to this. Instead, they really ought to have the FBI and the counterintelligence experts ask, “What would I do with this data if I were the Chinese?” and then ask people whose data has been exploited to look for that kind of behavior. Knowing how the Chinese do their recruiting I’m guessing they’re looking for people who have family still in China – grandmothers, mothers and the like, and who also work for the US government – and they will recruit them on the basis of ethnic and patriotic duty. And so folks who are in that situation could have their relatives visited for a little chat; there’s a lot of stuff that is unique to Chinese use of this data that we ought to be watching for a little more aggressively than stealing our credit.
Stewart: Yeah; well, that’s all we’ve got when it’s hackers. We should think of a new response to this.
Dan: We should, but like all hacks [attribution] is a pain in the butt because here’s the secret – hacking is not hard; teenagers can do it.
Stewart: Yes, that’s true.
Dan: [Something like this can take just] a few months.
Stewart: But why would they invest?
Dan: Why not? Data has value; they’ll sell it.
Stewart: Maybe; so that’s right. On the other hand the Anthem data never showed up in the markets. We have better intelligence than we used to. We’ll know if this stuff gets sold and it hasn’t been sold because – I don’t want to give the Chinese ideas but –
Dan: I don’t think they need you to give them ideas; sorry.
Stewart: One more story just to show that I was well ahead of the Chinese on this – my first security clearance they asked me for people with whom I had obligations of affection or loyalty, who were foreigners. And I said I’m an international lawyer – this was before you could just print out your Outlook contacts – I Xeroxed all those sheets of business cards that I’d collected, and I sent it to the guys and said, “These are all the clients or people I’ve pitched,” and he said, “There are like 1,000 names here.” I said, “Yeah, these are people that I either work for or want to work for.” And he said, “But I just want people to whom you have ties of obligation or loyalty or affection.” I said, “Well, they’re all clients and I like them and I have obligations to clients or I want them to be. I’ve pitched them.” And he finally stopped me and said, “No, no, I mean are you sleeping with any of them?” So good luck China, figuring out which of them, if any, I was actually sleeping with.
Dan: You see, you gave up all those names to China.
Stewart: They’re all given up.
Dan: Look what you did!
Stewart: Exactly; exactly. Okay, last a topic – Putin’s trolls – I thought this was fascinating. This is where the New York Times really distinguished itself with this article because it told us something we didn’t know and it shed light on kind of something astonishing. This is the internet association I think. Their army of trolls, and the Chinese have an even larger army of trolls, and essentially Putin’s FSB has figured out that if you don’t want to have a Facebook revolution or a Twitter revolution you need to have people on Twitter, on Facebook 24 hours a day, posting comments and turning what would otherwise be evidence of dissent into a toxic waste dump with people trashing each other, going off in weird directions, saying stupid things to the point where no one wants to read the comments anymore.
It’s now a policy. They’ve got a whole bunch of people doing it, and on top of it they’ve decided, “Hell, if the US is going to export Twitter and Twitter revolutions then we’ll export trolling,” and to the point where they’ve started making up chemical spills and tweeting them with realistic video and people weighing in to say, “Oh yeah, I can see it from my house, look at those flames.” All completely made up and doing it as though it were happening in Louisiana.
Dan: The reality is that for a long time the culture has managed. We had broadcasts, broadcasters had direct government links, everything was filtered, and the big experiment of the internet was what if we just remove those filters? What if we just let the people manage it themselves? And eventually astroturfing did not start with Russia; there’s been astroturfing for years. It’s where you have these people making fake events and controlling the message. What is changing is the scale of it. What is changing is who is doing it. What is changing is the organization and the amount of investment. You have people who are professionally operating to reduce the credibility of Twitter, of Facebook so that, quote/unquote, the only thing you can trust is the broadcast.
Stewart: I think that’s exactly right. I think they call the Chinese version of this the 50 Cent Army because they get 50 cents a post. But I guess I am surprised that the Russians would do that to us in what is plainly an effort to test to see whether they could totally disrupt our emergency response, and it didn’t do much in Louisiana but it wouldn’t be hard in a more serious crisis, for them to create panic, doubt and certainly uncertainty about the reliability of a whole bunch of media in the United States.
This was clearly a dry run and our response to it was pretty much that. I would have thought that the US government would say, “No, you don’t create fake emergencies inside the United States by pretending to be US news media.”
Jason: I was going to say all those alien sightings in Roswell in the last 50 years do you think were Russia or China?
Stewart: Well, they were pre Twitter; I’m guessing not but from now on I think we can assume they are.
Dan: What it all comes back to is the crisis of legitimacy. People do not trust the institutions that are around them. If you look there’s too much manipulation, too much skin, too many lives, and as it happens institutions are not all bad. Like you know what? Vaccines are awesome but because we have this lack of legitimacy people are looking to find what is the thing I’m supposed to be paying attention to, because the normal stuff keeps coming out that it was a lie and really, you know what, what Russia’s doing here is just saying, “We’re going to find the things that you’re going to instead, that you think are lying; we’re going to lie there too because what we really want is we want America to stop airing our dirty laundry through this Twitter thing, and if America is not going to regulate Twitter we’re just going to go ahead and make a mess of it too.”
Stewart: Yeah. I think their view is, “Well, Twitter undermines our legitimacy; we can use it to undermine yours?”
Dan: Yeah, Russians screwing with Americans; more likely than you think.
Michael: I’m surprised you guys see it as an effort to undermine Twitter; this strikes me as classic KGB disinformation tactics, and it seems to me they’re using a new medium and, as you said before, they’re doing dry runs so that when they actually have a need to engage in information operations against the US or against Ukraine or against some other country, they’ll know how to do it. They’ll have practiced cores of troll who know how to do this stuff in today’s media. I don’t think they’re trying to undermine Twitter.
Stewart: One of the things that interesting is that the authoritarians have figured out how to manage their people using electronic tools. They were scared to death by all of this stuff ten years ago and they’ve responded very creatively, very effectively to the point where I think they can maintain an authoritarian regime for a long time, without totalitarianism but still very effectively. And now they’re in the process of saying, “Well, how can we use these tools as a weapon the way they perceive the US has used the tools as weapon in the first ten years of social media.” We need a response because they’re not going to stop doing it until we have a response.
Michael: I’d start with the violation of the missile treaty before worrying about this so much.
Stewart: Okay, so maybe this is of a piece with the Administration’s strategy for negotiating with Russia, which is to hope that the Russians will come around. The Supreme Court had a ruling in the case we talked about a while ago; this is the guy who wrote really vile and threatening and scary things about his ex wife and the FBI agent who came to interview him and who said afterwards, after he’d posted on Facebook and was arrested for it, “Well, come on, I was just doing what everybody in hip hop does; you shouldn’t take it seriously. I didn’t,” and the Supreme Court was asked to decide whether the test for threatening action is the understanding of the writer or the understanding of the reader? At least that’s how I read it, and they sided with the writer, with the guy who wrote all those vile things. Michael, did you look more closely at that than I did?
Michael: The court read into it a requirement that the government has to show at least that the defendant sent the communication with the purpose of issuing a threat or with the knowledge that it would be viewed as a threat, and it wasn’t enough for the government to argue and a jury to find that a reasonable person would perceive it as a threat.
So you have to show at least knowledge or purpose or intent, and it left open the question whether recklessness as to how it would be perceived, was enough.
Stewart: All right; well, I’m not sure I’m completely persuaded but it probably also doesn’t have enough to do with CyberLaw in the end to pursue. Let’s close up with one last topic, which is the FBI is asking for or talking about expanding CALEA to cover social media, to cover communications that go out through direct messaging and the like, saying it’s not that we haven’t gotten cooperation from social media when we wanted it or a wiretap; it’s just that in many cases they haven’t been able to do it quickly enough and we need to set some rules in advance for their ability to do wiretaps.
This is different from the claim that they’re Going Dark and that they need access to encrypted communications; it really is an effort to actually change CALEA, which is the Communications Assistance Law Enforcement Act from 1994, and impose that obligation on cellphone companies and then later on voiceover IP providers. Jason, what are the prospects for this? How serious a push is this?
Jason: Well, prospects are – it’s DOA – but just to put it in a little bit of historical perspective. So Going Dark has of late been the name for the FBIs effort to deal with encryption, but the original use of that term, Going Dark was, at least in 2008/2009 when the FBI started a legislative push to amend CALEA and extend it to internet based communications, Going Dark was the term they used for that effort. They would cite routinely the fact that there was a very significant number of wiretaps in both criminal and national security case that providers that were not covered by CALEA didn’t have the technical capability to implement.
So it wasn’t about law enforcement having the authority to conduct a wiretap; they by definition has already definition had already developed enough evidence to satisfy a court that they could meet the legal standard. It was about the provider’s ability to help them execute that authority that they already had. As you suggested, either the wiretap couldn’t be done at all or the provider and the government would have to work together to develop a technical solution which could take months and months, by which time the target wasn’t using that method of communication anymore; had moved onto something else.
So for the better part of four years, my last four years at the department, the FBI was pushing along with DEA and some other agencies, for a massive CALEA reform effort to expand it to internet based communications. At that time – this is pre Snowden; it’s certainly truer now – but at that time it was viewed as a political non starter, to try to convince providers that CALEA should be expanded.
So they downshifted as a Plan B to try to amend Title 18, and I think there were some parallel amendments to Title 50, but the Title 18 amendments would have dramatically increased the penalties for provider who didn’t have the capability to implement a wiretap order, a valid wiretap order that law enforcement served.
There would be this graduating series of penalties that would essentially create a significant financial disincentive for a provider not to have in their sight capability in advance or to be able to develop one quite quickly. So the FBI, although it wanted CALEA to be expanded was willing to settle for this sort of indirect way to achieve the same thing; to incentivize providers to develop an intercept solutions.
That was an unlikely Bill to make it to the Hill and to make it through the Hill before Snowden; after Snowden I think it became politically plutonium. It was very hard even before Snowden to explain to people that this was not an effort to expand authorities; it was about executing those authorities. That argument became almost impossible to make in the post Snowden world.
What struck me about this story though is that they appear to be going back to Plan A, which is trying to go in the front door and expand CALEA, and the only thing I can interpret is either that the people running this effort now are unaware of the previous history that they went through, or they’ve just decided what the hell; they have nothing to lose. They’re unlikely to get it through anyway so they might as well ask for what they want.
Stewart: That’s my impression. There isn’t any likelihood in the next two years that encryption is going to get regulated, but the Justice Department and the FBI are raising this issue I think partly on what the hell, this is what we want, this is what we need, we might as well say so, and partly I think preparation of the battle space for the time when they actually have a really serious crime that everybody wishes had been solved and can’t be solved because of some of these technical gaps.
Dan: You know what drives me nuts is we’re getting hacked left and right; we’re leaking data left and right, and all these guys can talk about is how they want to leak more data. Like when we finish here this is about encryption. We’re not saying we’re banning encryption but if there’s encryption and we can’t get through it we’re going to have a graduated series of costs or we’re going to pull CALEA into this. There’s entire classes of software we need to protect American business that are very difficult to invest in right now. It’s very difficult to know, in the long term, that you’re going to get to run it.
Stewart: Well, actually my impression is that VCs are falling all over themselves to fund people who say, “Yeah, we’re going to stick it to the NSA.”
Dan: Yeah, but those of us who actually know what we’re doing, know whatever we’re doing, whatever would actually work, is actually under threat. There are lots of scammers out there; oh my goodness, there are some great, amazing, 1990s era snake oil going on, but the smart money is not too sure we’re going to get away with securing anything.
Stewart: I think that’s probably right; why don’t we just move right in because I had promised I was going to talk about this from the news roundup to this question – Julian Sanchez raised it; I raised it with Julian at a previous podcast. We were talking about the effort to get access to encrypted communications and I mocked the people who said, “Oh, you can never provide access without that; that’s always a bad idea.” And I said, “No, come on.” Yes, it creates a security risk and you have to manage it but sometimes the security risk and the cost of managing it is worth it because of the social values.
Dan: Sometimes you lose 30 years of background check data.
Stewart: Yeah, although I’m not sure they would have. I’m not sure how encryption, especially encryption of data in motion, would have changed that.
Dan: It’s a question of can you protect the big magic key that gives you access to everything on the Internet, and the answer is no.
Stewart: So let me point to the topic that Julian didn’t want to get into because it seemed to be more technical than he was comfortable with which is –
Dan: Bring it on.
Stewart: Exactly. I said, “Are you kidding me? End to end encryption?” The only end to end encryption that has been adopted universally on the internet since encryption became widely exportable is SSL/TLS. That’s everywhere; it’s default.
Okay, but SSL/TLS is broken every single day by the thousands, if not the millions, and it’s broken by respectable companies. In fact, probably every Fortune 500 company insists that SSL has to be broken at their firewall.
And they do it; they do it so that they can inspect the traffic to see whether some hacker is exfiltrating the –
Dan: Yeah, but they’re inspecting their own traffic. Organizations can go ahead and balance their benefits and balance their risks. When it’s an external actor it’s someone else’s risk. It’s all about externality.
Stewart: Well, yes, okay; I grant you that. The point is the idea that building in access is always a stupid idea, never worth it. It’s just wrong, or at least it’s inconsistent with the security practices that we have today. And probably, if anything, some of the things that companies like Google and Facebook are doing to promote SSL are going to result in more exfiltration of data. People are already exfiltrating data through Google properties because Google insists that they be whitelisted from these intercepts.
Dan: What’s increasingly happening is that corporations are moving the intercept and DLP and analytics role to the endpoint because operating it as a midpoint just gets slower and more fragile day after day, month after month, year after year. If you want security, look, it’s your property, you’re a large company, you own 30,000 desktops, they’re your desktops, and you can put stuff on them.
Stewart: But the problem that the companies have, which is weighing the importance of end to end encryption for security versus the importance of being able to monitor activity for security, they have come down and said, “We have to be able to monitor it; we can’t just assume that every one of our users is operating safely.” That’s a judgment that society can make just as easily. Once you’ve had the debate society can say, “You know, on the whole, ensuring the privacy of everybody in our country versus the risks of criminals misusing that data, we’re prepared to say we can take some risk on the security side to have less effective end to end encryption in order to make sure that people cannot get away with breaking the law with impunity.”
Dan: Here’s a thing though – society has straight out said, “We don’t want bulk surveillance.” If you want to go ahead and monitor individuals, you have a reason to monitor, that’s one thing but –
Stewart: But you can’t monitor all of them. If they’ve been given end to end – I agree with you – there’s a debate; I’m happy to continue debating it but I’ve lost so far. But you say, no, it’s this guy; this guy, we want to listen to his communications, we want to see what he is saying on that encrypted tunnel, you can’t break that just stepping into the middle of it unless you already own his machine.
Dan: Yeah, and it’s unfortunately the expensive road.
Stewart: because they don’t do no good.
Dan: isn’t there. It isn’t the actual thing.
Stewart: It isn’t here – I’m over at Stanford and we’re at the epicenter of a contempt for government, but everybody gets a vote. You get a vote if you live in Akron, Ohio too, but nobody in Akron gets a vote about where their end to end encryption is going to be deployed.
Dan: You know, look, average people, normal people have like eight secure messengers on their phone. Text messaging has fallen off a cliff; why? At the end of the day it’s because people want to be able to talk to each other and not have everyone spying on them. There’s a cost, there’s an actual cost to spying on the wrong people.
Stewart: There is?
Dan: If you go ahead and you make everyone your enemy you find yourself with very few friends. That’s how the world actually works.
Stewart: All right; I think we’ve at least agreed that there’s routine breakage of the one end to end encryption methodology that has been widely deployed. I agree with you, people are moving away from man in middle and are looking to find ways to break into systems at the endpoint or close to the endpoint. Okay; let’s talk a little bit, if we can, about DNSSEC because we had a great fight over SOPA and DNSSEC, and I guess the question for me is what – well, maybe you can give us two seconds or two minutes on what DNSSEC is and how it’s doing in terms of deployment.
Dan: DNSSEC, at the end of the day makes it as easy to get encryption keys as it is to get the address for a server. Crypto should not be drama. You’re a developer, you need to figure out how to encrypt something, hit the encrypt button, you move on with your life. You write your app. That’s how it needs to work.
DNS has been a fantastic success at providing addressing to the internet. It would be nice if keying was just as easy, but let me tell you, how do you go ahead and go out and talk to all these internet people about how great DNSSEC is when really it’s very clear DNS itself – it’s not like SOPA fights, it’s not going to come back –
Stewart: Yeah; well, maybe.
Dan: – and it’s not like the security establishment, which should be trying to make America safer, it’s like, “Man, we really want to make sure we get our keys in there.” When that happens [it doesn’t work]. It’s not that DNSSEC isn’t a great technology, but it really depends on politically [the DNS and its contents] being sacrosanct.
Stewart: Obviously, DHS, the OMB committed to getting DNSSEC deployed at the federal level, and so their enthusiasm for DNSSEC has been substantial. Are you saying that they have undermined that in some way that –
Dan: The federal government is not monolithic; two million employees, maybe more, and what I’m telling you is that besides the security establishment that’s keeping on saying, “Hey, we’ve got to be able to get our keys in there too,” has really – we’ve got this dual mission problem going on here. Any system with a dual mission, no one actually believes there’s a dual mission, okay.
If the Department of Transportation was like, “Maybe cars should cars should crash from time to time,” if Health or Human Services was like, “Hey, you know, polio is kind of cool for killing some bad guys.” No one would take those vaccines because maybe it’s the other mission and that’s kind of the situation that we have right here. Yeah, DNSSEC is a fantastic technology for key distribution, but we have no idea five years from now what you’re going to do with it, and so instead it’s being replaced with garbage [EDIT: This is rude, and inappropriate verbiage.]
I’m sorry, I know people are doing some very good work, but let me tell you, their value add is it’s a bunch of centralized systems that all say, “But we’re going to stand up to the government.” I mean, that’s the value add and it never scales, it never works but we keep trying because we’ve got to do something because it’s a disaster out there. And honestly, anything is better than what we’ve got, but what we should be doing is DNSSEC and as long as you keep making this noise we can’t do it.
Stewart: So DNSSEC is up to what? Ten percent deployment?
Dan: DNSSEC needs a round of investment that makes it a turnkey switch.
Stewart: Aah!
Dan: DNSSEC could be done [automatically] but every server just doesn’t. We [could] just transition the internet to it. You could do that. The technology is there but the politics are completely broken.
Stewart: Okay; last set of questions. You’re the Chief Scientist at WhiteOps and let me tell you what I think WhiteOps does and then you can tell me what it really does. I think of WhiteOps as having made the observation that the hackers who are getting into our systems are doing it from a distance. They’re sending bots into pack up and exfiltrate data. They’re logging on and bots look different from human beings when they type stuff and the people who are trying to manage an intrusion remotely also looks different from somebody who is actually on the network and what WhiteOps is doing is saying, “We can find those guys and stop them.”
Dan: And it’s exactly what we’re doing. Look, I don’t care how clever your buffer overflow is; you’re not teleporting in front of a keyboard, okay. That’s not going to happen. So our observation is that we have this very strong signal, it’s not perfect because sometimes people VPN in, sometimes people make scripted processes.
Stewart: But they can’t keep a VPN up for very long?
Dan: [If somebody is remotely] on the machine; you can pick it up in JavaScript. So you have a website that’s being lilypad accessed either through bulk communications with command and control to a bot, or through interaction with remote control, churns out weak signals that we’re able to pick up in JavaScript.
Stewart: So this sounds so sensible and so obvious that I guess my question is how come we took this long to have that observation become a company?
Dan: I don’t know but we built it. The reality is, is that it requires knowledge of a lot of really interesting browser internals. At WhiteOps we’ve been breaking browsers for years so we’re basically taking all these bugs that actually never let you attack the user but they have completely different responses inside of a bot environment. That’s kind of the secret sauce.
Every browser is really a core object that reads HTML 5, Java Scripted video, all the things you’ve got to do to be a web browser. Then there’s like this goop, right? Like it puts it on the screen, it has a back button, uses an address bar, and lets you configure stuff, so it turns out that the bots use the core not the goop.
Stewart: Oh yeah, because the core enables them to write one script for everything?
Dan: Yeah, so you have to think of bots as really terribly tested browsers and once you realize that it’s like, “Oh, this is barely tested, let’s make it break.”
Stewart: Huh! I know you’ve been doing work with companies looking for intrusions. You’ve also been working with advertisers; not trying to find people who are basically engaged in click fraud. Any stories you can tell about catching people on well guarded networks?
Dan: I think one story I really enjoy – we actually ran the largest study into ad fraud that had ever been done, of its nature. We found that there’s going to be about $6 billion of ad fraud at http://whiteops.com/botfraud, and we had this one case, so we tell the world we’re going to go ahead and run this test in August and find all the fraud. You know what? We lied. We do that sometimes.
We actually ran a test from a little bit in July, all the way through September and we watched this one campaign; 40 percent fraud, then when we said we were going to start, three percent fraud. Then when we said we’re going to start, back to 40. You just had this square wave. It was the most beautiful demo. We showed this to the customers – one of the biggest brands in the country – and they were just like, “Those guys did what?”
And here’s what’s great – for my entire career I’ve been dealing with how people break in. This bug, that bug, what’s wrong with Flash, what’s wrong with Java? This is the first time in my life I have ever been dealing with why. People are doing this fraud to make money. Let’s stop the checks from being written? It’s been incredibly entertaining.
Stewart: Oh, that it is; that’s very cool, and it is – I guess maybe this is the observation. We wasted so much time trying to keep people out of systems hopelessly; now everybody says, “Oh, you have to assume they’re in,” but that doesn’t mean you have the tools to really deal with them, and this is a tool to deal with people when they’re in.
Dan: There’s been a major shift from prevention to detection. We basically say, “Look, okay, they’re going to get in but they don’t necessarily know what perfectly to do once they’re in.” Their actions are fundamentally different than your legitimate users and they’re always going to be because they’re trying to do different things; so if you can detect properties of the different things that they’re doing you actually have signals, and it always comes down to signals in intelligence.
Stewart: Yeah; that’s right. I’m looking forward to NSA deploying WhiteOps technology, but I won’t ask you to respond to that one. Okay, Dan, this was terrific I have to say. I’d rather be on your side of an argument than against you, but it’s been a real pleasure arguing this out. Thanks for coming in Michael, Jason; I appreciate it.
Just to close up the CyberLaw Podcast is open to feedback. Send comments to cyberlawpodcast@steptoe.com; leave a message at 202 862 5785. I’m still waiting for an entertainingly abusive voicemail. We haven’t got them. This has been episode 70 of the Steptoe CyberLaw Podcast brought to by Steptoe & Johnson. Next week we’re going to be joined by Catherine Lotrionte, who is the Associate Director of the Institute for Law, Science and Global Security at Georgetown. And coming soon we’re going to have Jim Baker, the General Counsel of the FBI; Rob Knake, a Senior Fellow for Cyber Policy at the Council on Foreign Relations. We hope you’ll join us next week as we once again provide insights into the latest events in technology, security, privacy in government.

{kind=link}